Network Pruning that Matters: A Case Study on Retraining Variants
June 14, 2021
Introduction
Training neural networks is an everyday task in the era of deep learning and artificial intelligence. Generally speaking, given data availability, large and cumbersome networks are often preferred as they have more capacity to exhibit good data generalization. In the literature, large networks are considered easier to train than small ones. Thus, many breakthroughs in deep learning are strongly correlated to increasingly complex and over-parameterized networks. However, the use of large networks exacerbate the gap between research and practice since real-world applications usually require running neural networks in low-resource environments for numerous purposes: reducing memory, latency, energy consumption, etc. To adopt those networks to resource constrained devices, network pruning is often exploited to remove dispensable weights, filters and other structures from neural networks. The goal of pruning is to reduce overall computational cost and memory footprint without inducing significant drop in performance of the network.
Motivation
A common approach to mitigating performance drop after pruning is retraining: we continue to train the pruned models for some more epochs. This seemly subtle step is often overlooked when designing pruning algorithms: we found that the implementation of previous pruning algorithms have many notable differences in their retraining step. Despite such difference, the success of each pruning algorithm is only attributed to the pruning algorithm itself. This motivates us to ask the question: do details like learning rate schedule used for retraining matter?
Approach
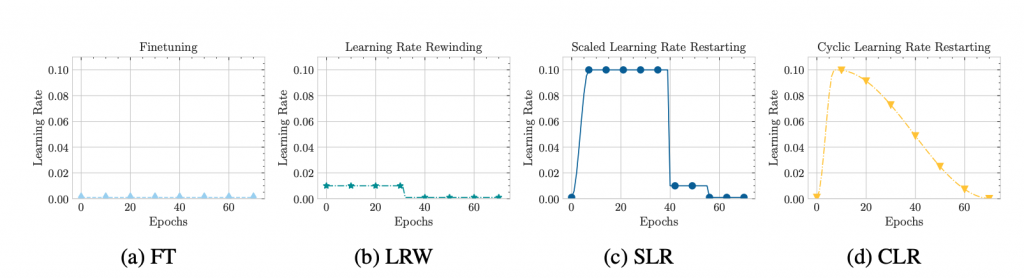
We conduct experiments with different learning rate schedules including learning rate rewinding (Renda et al., 2020) while varying pruning algorithms, network architectures and datasets. These schedules are illustrated in Figure 1. Particularly, they vary in learning rate value, decay function, etc.
Figure 1: Learning rate with different schedules on CIFAR when retraining for 72 epochs. In (a), the learning rate is fixed to the last learning rate of original training (i.e. 0.001). In (b), the learning rate is ”rewound” to previous 72 epochs (which is 0.01), and is dropped to 0.001 after 32 epochs. In (c), after warming up the learning rate, we drop its value by the factor of 10× at 50% and 75% of remaining epochs. In (d), we warm up the learning rate from the lowest to the highest value (of standard training) for the first few epochs, then decay the learning rate according to cosine function.
Experiment Results
1. Simple baseline with l1 -norm pruning
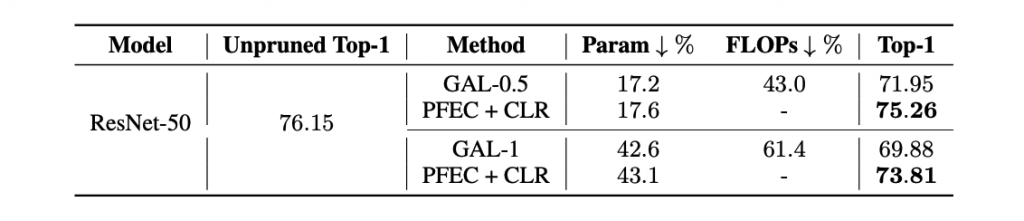
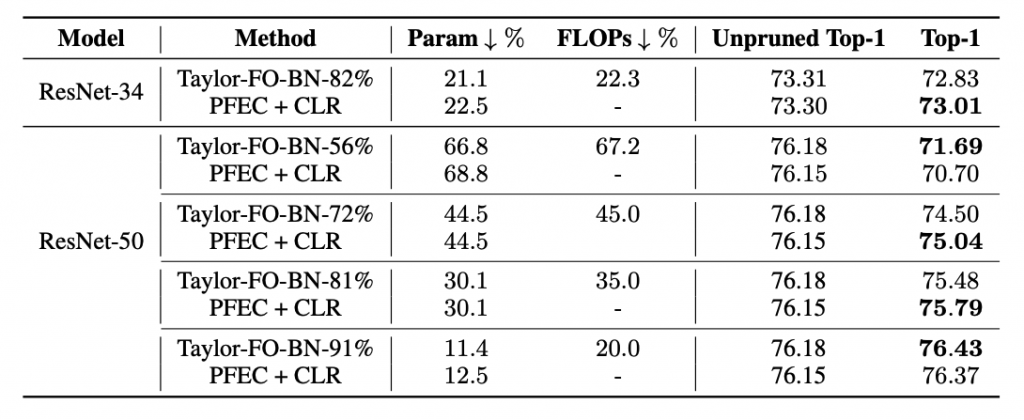
We demonstrate that even with same retraining budgets, utilizing simple CLR with l1-norm filters (i.e. PFEC) pruning can achive comparable or exceed the performance of more sophisticated saliency metrics without meticulous hyperparameters searching.
Comparing the performance of pruned network via PFEC with CLR and GAL on ImageNet. The results of GAL are taken directly from original papers.
Comparing the performance of pruned network via PFEC + CLR and Taylor Pruning on ImageNet. The results of Taylor Pruning are taken directly from original papers.
2. Random Pruning
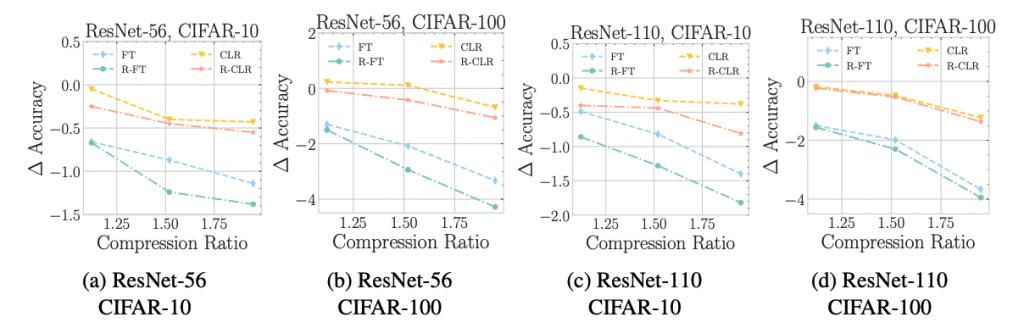
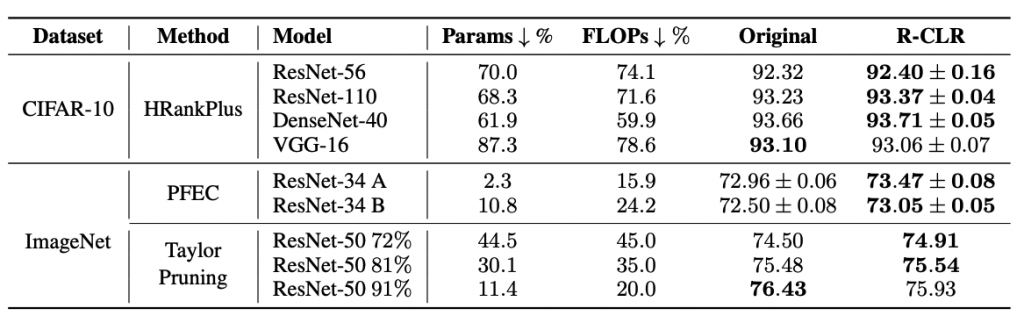
We investigate the interplay between pruning saliency metrics and retraining configurations by comparing accuracy of randomly pruned networks with the original performance of methodically pruned networks. Surprisingly, we found that even random pruning with “optimal” learning rate schedule (while keeping all other hyperparameters) can outperform sophisticated pruning algorithm in numerous circumstances.
First we consider the simple norm pruning on small dataset such as CIFAR-10 and illustrate the result in Figure 2 below. We can see that randomly pruned networks consistently achieve superior performance than methodically pruned networks (fine-tuned with standard learning rate schedule) in terms of accuracy. However, random pruning obtain lower accuracy than l1-norm pruning when using identical retraining techniques.
Figure 2: One-shot structured pruning on CIFAR-10 dataset using l1-norm pruning (Li et al., 2016) and randomly filters pruning with different retraining schemes
Next, we consider a large-scale dataset such as Imagenet with more advanced pruning algorithms and also observed the same phenomenon.
Results of networks when applying random pruning and methodically pruning algorithms. ‚”Original” column presents accuracy of pruned network reported in original papers. “R-CLR” presents the results of Random Pruning with CLR.
Conclusion
These results suggest that retraining techniques, e.g., learning rate restarting and learning rate schedule, play a pivotal role to final performance. Thus, in order to perform fair comparison of different methods, one should be cautious of this seemingly subtle detail.
Reference
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets.
Alex Renda, Jonathan Frankle, and Michael Carbin. Comparing rewinding and fine-tuning in neural network pruning.