Unsupervised Domain Adaptation for Event Detection using Domain-specific Adapters
December 22, 2021
Introduction
Event detection (ED) is an important component in the overall event extraction pipeline, which plays a crucial role in any natural language understanding system. Tackling ED problem involves both locating the event triggers and categorizing them into specific event types, therefore can be a quite challenging task due to the intricate dependency among triggers, events, and contexts in linguistic data. The complication is further amplified by domain shift problem when texts are collected from multiple different domains. In this paper, our work explores the general problem of domain adaptation for ED where data comes from two different source and target domains. In particular, we focus on the unsupervised learning setting that requires no annotation for target data, and the model has to learn to make use of both labeled source and unlabeled target samples to improve its performance on target domain.
Motivation
Due to the multi-dimensional variation of textual data, detection of event triggers from new domains can become a lot more challenging. This prompts a need to research on domain adaptation methods for event detection task, especially for the most practical setting of supervised learning. Recently, large transformer-based language models, e.g. BERT, have become essential to achieve top performance for event detection. However, their unwieldy nature also prevents effective adaptation across domains. To this end, we propose a Domain-specific Adapter-based Adaptation (DAA) framework to improve the adaptability of BERT-based models for event detection across domains.
Contributions
By explicitly representing data from different domains with separate adapter modules in each layer of BERT, DAA introduces a novel joint representation learning mechanism to extract domain-invariant features.
We also introduce a Wasserstein distance-based technique for data selection to substantially boost robustness and performance of models on target domains.
Extensive experiments and analysis over different datasets (i.e., LitBank, TimeBank, and ACE-05) demonstrate the effectiveness of our approach.
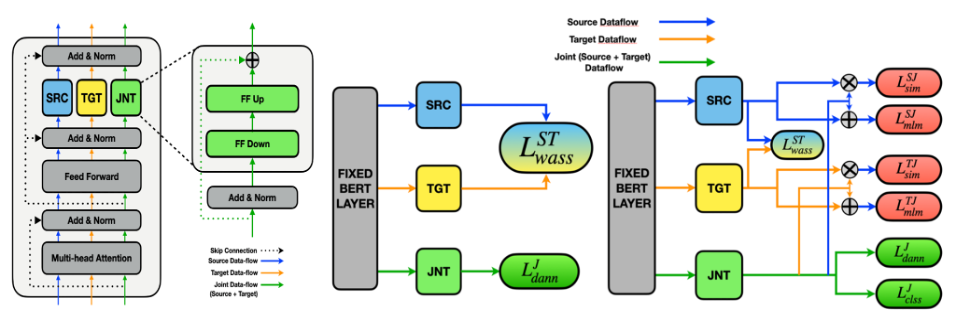
The overall architecture of our framework is depicted in figure 1. First, adapter-based fine-tuning (Houlsby et al., 2019) is leveraged to efficiently create domain-specific representations without having to duplicate the whole model. These representations are then trained to extract domain-invariant features through a modified domain-adversarial neural network (DANN) (Ganin et al., 2015). Finally, a data selection mechanism is employed based on the Wasserstein distance (Shen et al., 2018) between samples of source and target domain to improve the robustness of the framework.
The whole learning process is alternated between divergence steps and representation steps. The former is repeated k times to accurately approximate the divergences between domains, whereas the latter uses the previously computed distance to update parameters of adapters and other downstream tasks.
Experiment Settings
The Automatic Content Extraction 2005 (ACE-05) dataset is a densely annotated corpus collected from 6 different domains: Newswire (nw) – 20%, Broadcast news (bn) – 20%, Broadcast conversation (bc) – 15%, Weblog (wl) – 15%, Usenet Newsgroups (un) – 15%, Conversational Telephone Speech (cts) – 15%. Events of the dataset are categorized into 33 types.
We combine samples from two closely related domains, nw and bn, to create a sizable labeled training source dataset. Then, each of the other domains is considered the target domain of a single adaptation setting. Performance of each trained model is measured in precision (P), recall (R), and F1 scores.
Domain Adaptation Results
Table 1: Unsupervised domain adaptation for event detection. Performance on the ACE-05 test datasets for different domains.
Table 1 showcases the results of our event detection experiment. The main conclusions from the table include:
The BERT baseline performs decently without using any mechanism to address the discrepancy between domains. However, naively adopting DANN for BERT has an adverse effect, notably reducing the performance of BERT+DANN on all target domains.
The results of BERT+Adapter proves that adapter-based fine-tuning procedure is not only able to retain performance but also prevent over-fitting through capacity reduction.
Finally, our proposed model DAA manages to achieve the best adaptation performance across all target domains. Especially, DAA significantly outperforms baselines (3 to 5 points increase in F1 score) when transferring to target domains that are highly dissimilar to source domains (i.e., wl and un).
Conclusion
We present a novel framework for ED in the unsupervised domain adaptation setting that effectively leverages the generalization capability of large pre-trained language models through a shared-private adapter-based architecture. A layer-wise domain-adversarial training process combined with Wasserstein-based data selection addresses the discrepancy between domains and produces domain-invariant representations. The proposed model achieves state-of-the-art results on several adaptation settings across multiple domains.
Reference
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for NLP. Proceedings of the 36th International Conference on Machine Learning (ICML)
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, Francois Laviolette, Mario Marchand, and Victor Lempitsky. 2016. Domain-adversarial training of neural networks. The Journal of Machine Learning Research, 17(1):2096–2030.
Jian Shen, Yanru Qu, Weinan Zhang, and Yong Yu. Wasserstein distance guided representation learning for domain adaptation. In AAAI, 2018.