RecGPT: Generative Pre-training for Text-based Recommendation
September 19, 2024
Motivation
Recommendation systems assist in comprehending user preferences and offering suitable content suggestions for users. Currently, recommendation systems have found wide applications across various domains, such as e-commerce, news, and movies. The evolution of recommendation systems has witnessed a shift from fundamental methods to more sophisticated and modern approaches. Conventional methods mine interaction matrices to exploit user-item relationship. However, this task-specific setting suffers from data sparsity, a lack of flexibility to capture fluctuations in user preferences over time, and challenges in scaling to a large number of users and extensive datasets. Later works, inspired by attention mechanisms and the Transformers architecture, model user histories as sequences of items and then encode information in dense vectors.
With the advancement of large language models (LLMs), recent works leverage the capacity of LLMs in understanding user preferences. The model P5, which represents users and items by IDs, endeavors to aggregate recommendation tasks under a unified conditional generation model based on T5. In addition, Liu et al. (2023) evaluate the potential usage of ChatGPT in different recommendation tasks. More recently, Ji et al. (2024) fine-tune LLaMA with LoRA for sequential recommendation. Recommendation tasks frequently exhibit shared characteristics such as user sets, item sets, and interactions, thus suggesting the possibility of training a unified model for multiple tasks, as opposed to employing distinct models for each task. Adopting a single model approach, as done in P5, not only encourages model generalization but also fosters collaborative learning across tasks. However, representing users and items by IDs, as in P5, may not fully align with the textual understanding capability of LLMs. It might be more effective to represent items by their textual descriptions and users by their text-based interaction history with items.
Our model RecGPT
Pre-training and Fine-tuning data
We collect a rich and comprehensive set of datasets from various domains, including: Amazon Product, Anime, BookCrossing, Food, Goodreads, HotelRec, MovieLens, Netflix, Steam, WikiRec, and Yelp. Specifically, we select datasets that contain item titles, a key factor for item representation. Each item is associated with metadata comprising attributes such as title and brand, along with user interactions such as rating and review. We perform a cleaning pre-process on the collected datasets by discarding: (i) items without titles, (ii) users with fewer than 5 interactions, and (iii) all background and demographic user information. Ultimately, we have 10,156,309 users, 10,309,169 items, and 258,100,698 interactions in total.
Then we randomly split each cleaned dataset into pre-training/fine-tuning subsets with a 99.5/0.5 ratio at the “user” level (i.e., users in the fine-tuning subset do not appear in the pre-training subset, and vice versa). Regarding pre-training, users are represented solely through their interaction history with items. Each user’s interaction history, referred to as a text document, is formatted as a chronologically-ordered list of text-based data points i1 , i2 , …, in , where ik is represented by the corresponding k-th item’s metadata and interactions. For example, in the pre-training sample in Table 1, i1 is “Title: Rock-a-Stack; Brand: Fisher-Price; Review: My son loves to empty this stacker and play with and teeth on the rings; Rating: 5.0/5.0”. Totally, we create a pre-training corpus of 10M+ documents with 20.5B tokens.
When it comes to fine-tuning for instruction following, given the nature of our datasets, we create prompt-response pairs for two popular tasks in the recommendation system domain: rating prediction and sequential recommendation. For each user with the history i1 , i2 , …, in , the last item in is considered as the next item to be predicted in sequential recommendation, given the history context i1 , i2 , …, in−1 . Meanwhile, the rating of the (n − 1)-th item in−1 is used as the label for rating prediction, given the remaining history context i1 , i2 , …, in−1 without the rating of the (n − 1)-th item. Depending on task requirements, unused features within each data point ik of the user history are discarded, streamlining the prompts and their responses for enhanced task relevance and efficiency. Altogether, we create a fine-tuning dataset of 100K+ instructional prompt and response pairs.
Examples of a pre-training document and prompt-response pairs are shown in Table 1.
Table 1: Pre-training and fine-tuning data examples.
RecGPT-7B & RecGPT-7B-Instruct
RecGPT-7B is a Transformer decoder-based model that incorporates (Triton) flash attention and ALiBi for context length extrapolation. Additionally, we use a “max_seq_len” of 2048, “d_model” of 4096, “n_heads” of 32, “n_layers” of 32, and GPT-NeoX’s tokenizer with a vocabulary of 50K tokens, resulting in a model size of about 7B parameters. Utilizing the Mosaicml “llm-foundry” library, we initialize the parameter weights of RecGPT-7B with those from the pretrained MPT-7B and continually pretrain on our pre-training corpus of 20.5B tokens. For optimization, we employ the LION optimizer and sharded data parallelism with FSDP, set a global batch size of 128 (i.e., 128 * 2048 = 260K tokens per batch) across 8 A100 GPUs (40GB each), and use a peak learning rate of 2.5e-5. The training runs for 2 epochs, using mixed precision training with bfloat16, and takes about 18 days.
We then fine-tune the base pre-trained RecGPT-7B for instruction following regarding rating prediction and sequential recommendation, using the dataset consisting of 100K+ instructional prompts and responses. The resulting fine-tuned model is named RecGPT-7B-Instruct.
Experiments
Experimental setup
Evaluation datasets: We carry out experiments on 4 benchmark datasets across different domains, including “Amazon Beauty”, “Amazon Sports and Outdoors” and “Amazon Toys and Games”, as well as Yelp. Following previous works, for those three Amazon datasets, we employ the 5-core version 2014, while for Yelp, we consider transactions from Jan 1, 2019, to Dec 31, 2019.
For a consistent test set, we still reuse their splits but remove interactions from the training set if they appear in the test set. This ensures that the test data is not leaked into the training data. Note that for these 4 experimental benchmarks, we report our final scores on the test split, while the training split is only used for pre-training RecGPT-7B to mimic real-world scenarios (i.e., we do not use the training/validation split for supervised fine-tuning of instruction following).
Evaluation metrics: For rating prediction, we employ Root Mean Square Error (RMSE) and Mean Absolute Error (MAE), while for sequential recommendation, we use top-k Hit Ratio (HR@k) and top-k Normalized Discounted Cumulative Gain (NDCG@k). Smaller values of RMSE and MAE, and higher values of HR and NDCG, indicate better Performance.
Inference: For rating prediction, for a given input prompt, we apply the sampling decoding strategy with “temperature” of 1.0, “top_p” of 0.9 and “top_k” set at 50, and then extract the predicted value from the generated response output. For sequential recommendation, following previous works, for a given input prompt, we use the beam search decoding strategy with a beam size of 10 to generate 10 response outputs and use their beam search scores for ranking.
Main results
Table 2: Results obtained for rating prediction: “Sport” and “Toys” abbreviate “Sports and Outdoors” and “Toys and Games”, respectively.
Rating prediction: Table 2 lists rating prediction results for our RecGPT-7B-Instruct and the previous strong baselines on the four experimental datasets. We find that, in general, pre-trained LLM-based approaches, specifically P5, ChatGPT, and RecGPT-7B-Instruct, outperform conventional rating prediction methods MF and MLP. Although ChatGPT is not specifically designed for this task, it demonstrates promising performance scores that surpass those of P5 on the “Beauty” dataset. We find that RecGPT-7B-Instruct achieves the best results across all datasets in terms of both evaluation metrics RMSE and MAE, yielding new state-of-the-art performance scores.
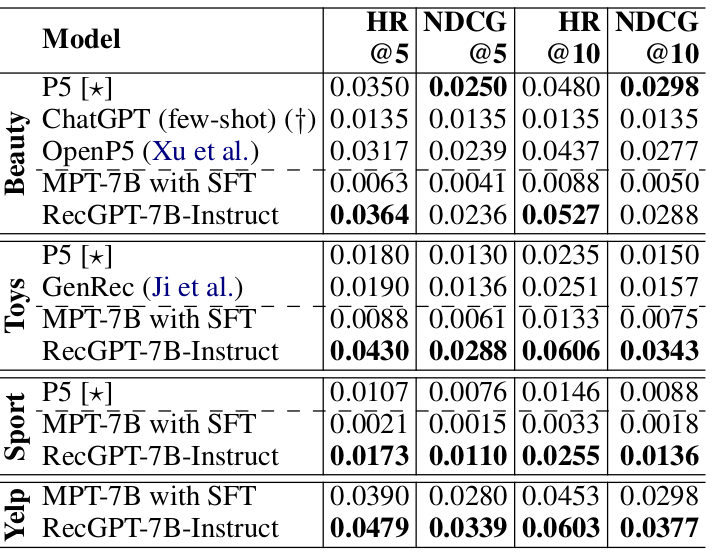
Table 3: Results obtained for sequential recommendation.
Sequential recommendation: Table 3 presents the obtained results with cutoff thresholds of 5 and 10 for HR and NDCG for different models on the sequential recommendation task. Not surprisingly, ChatGPT, which faces a limitation in terms of indomain data, attains lower scores than other baselines on the “Beauty” dataset. This highlights the crucial role of in-domain training data in sequential recommendation for models to comprehend the item set. GenRec, fine-tuned with LoRa on the entire training split, does not perform competitively on the “Toys and Games” dataset, compared to the fully finetuned model RecGPT-7B-Instruct. Additionally, our RecGPT-7B-Instruct achieves competitive results with P5 and OpenP5 on the “Beauty” dataset. Moreover, RecGPT-7B-Instruct notably outperforms P5 on both the “Sports and Outdoors” and “Toys and Games” datasets.
Conclusion
We have introduced the first domain-adapted and fully-trained LLMs for text-based recommendation, which include the base pre-trained RecGPT-7B and its instruction-following variant, RecGPT-7B-Instruct. We demonstrate the usefulness of RecGPT by showing that RecGPT-7B-Instruct outperforms strong baselines in both rating prediction and sequential recommendation tasks. Through the public release of RecGPT models and the pre-training and supervised fine-tuning datasets, we hope that they can foster future research and applications in text-based recommendation.