Textual Manifold-based Defense Against Natural Language Adversarial Examples
October 25, 2022
1. Introduction
The field of NLP has achieved remarkable success in recent years, thanks to the development of large pretrained language models (PLMs). However, multiple studies have shown that these models are vulnerable to adversarial examples – carefully optimized inputs that cause erroneous predictions while remaining imperceptible to humans [1, 2]. This problem raises serious security concerns as PLMs are widely deployed in many modern NLP applications.
2. Motivation
Concurrent with the streams of attack and defense research, numerous efforts have been made to understand the characteristics of adversarial examples [3-8]. One rising hypothesis is the off-manifold conjecture, which states that adversarial examples leave the underlying low-dimensional manifold of natural data [5, 6, 9, 10]. This observation has inspired a new line of defenses that leverage the data manifold to defend against adversarial examples, namely manifold-based defenses [11-13]. Despite the early signs of success, such methods have only focused on images. It remains unclear if the off-manifold conjecture also generalizes to other data modalities such as texts and how one can utilize this property to improve models’ robustness.
3. Our contributions
In this study, we empirically show that the off-manifold conjecture indeed holds in the contextualized embedding space of textual data. Based on this finding, we develop Textual Manifold-based Defense (TMD), a novel method that leverages the manifold of text embeddings to improve NLP robustness. Our approach consists of two key steps: (1) approximating the contextualized embedding manifold by training a generative model on the continuous representations of natural texts, and (2) given an unseen input at inference, we first extract its embedding, then use a sampling-based reconstruction method to project the embedding onto the learned manifold before performing standard classification. TMD has several benefits compared to previous defenses: (1) our method is cost-efficient since it does not require finetuning or adversarially finetuning the victim classifier, and (2) our method is structure-free, i.e., it can be easily adapted to different model architectures. The results of extensive experiments under diverse adversarial settings show that our method consistently outperforms previous defenses by a large margin.
4. Textual Manifold-based Defense
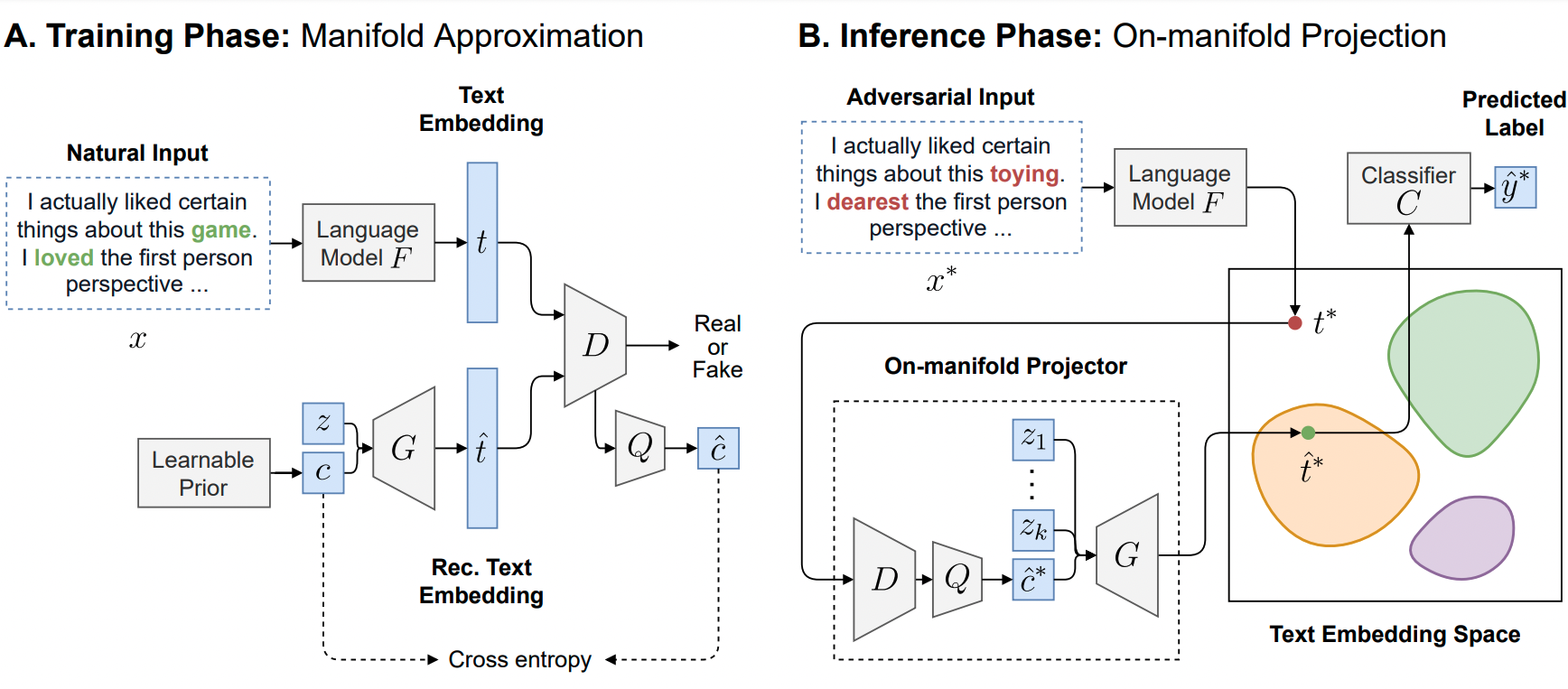
Figure 1: Overview of Textual Manifold-based Defense
The overview of our defense is depicted in the figure above. Our defense consists of two phases:
Training phase: all textual inputs are transformed into continuous representations . An InfoGAN [14] with learnable prior is trained to distinguish between real embeddings versus fake embeddings to implicitly learn the natural text embedding manifold.
Inference phase: once the generative model is trained, novel input embedding is projected onto the approximated manifold using a sampling-based reconstruction strategy. The reconstructed embedding is fed to the classifier to produce the final predicted label . The colored blobs represent the approximated disjoint submanifolds in the contextualized embedding space.
5. Validating the Off-Manifold conjecture in NLP
Figure 2: Distributions of , , and .
Equipped with a way to approximate the contextualized embedding manifold, we aim to validate the off-manifold conjecture in the NLP domain. To achieve this, we first compute the distances of natural and adversarial embeddings to the approximated manifold , denoted as and , respectively.
The off-manifold conjecture states that adversarial examples tend to leave the underlying natural data manifold. Therefore, if the off-manifold conjecture holds, we should observe small for clean examples, while adversarial examples have large values of .
For each sentence in the test set, we find its corresponding adversarial example . Additionally, to ensure that large is not simply caused by word substitution, we randomly substitute with synonyms to make an augmented sentence and see if the resulted distribution diverges away from . We set the modifying ratio equal to the average percentage of perturbed words in for a fair comparison. The distributions of , , and are visualized in the figure above.
From the figure, we can see a clear divergence between the distribution of and on all models. Furthermore, the distribution remains nearly identical to . This shows that simple word substitution does not cause the embedding to diverge off the natural manifold. Additionally, it is important to emphasize that since all are unseen examples from the test set, low values of are not simply due to overfitting in the generative model. These results provide empirical evidence to support the off-manifold conjecture in NLP.
6. Experiments
6.1. Experimental settings
– Datasets: we evaluate our method on three datasets: AGNEWS, IMDB, and Yelp Polarity. Due to limitations in computing resources, we only use a subset of 63000 samples of the YELP dataset. In addition, we randomly sample 10% of the training set for validation in all datasets.
– Model Architectures: to test if our method is able to generalize to different architectures, we apply TMD on three state-of-the-art pretrained language models: BERT, RoBERTa, and XLNet.
– Adversarial Attacks: We choose the following state-of-the-art attacks to measure the robustness of our method: PWWS [15], TextFooler [16], and BERT-Attack [17].
For a fair comparison, we follow the same settings as [18], in which all attacks must follow the following constraints: (1) the maximum percentage of modified words for AGNEWS, IMDB, and YELP must be , , and respectively, (2) the maximum number of candidate replacement words is set to , (3) the minimum semantic similarity\footnote{The semantic similarity between and is approximated by measuring the cosine similarity between their text embeddings produced from Universal Sentence Encoder \cite{cer-etal-2018-universal}} between original input and adversarial example must be , and (4) the maximum number of queries to the victim model is , where is the length of the original input .
– Baseline Defenses: We compare our method with other families of defenses. For adversarial training defenses, we use the Adversarial Sparse Convex Combination (ASCC) [19] and Dirichlet Neighborhood Ensemble (DNE) [20]. For certified defenses, we use SAFER [21].
6.2. Main results
Figure 3: Results for the AGNEWS, IMDB, YELP datasets
To evaluate the robustness of different defenses, we randomly select 1000 samples from the test set and evaluate their accuracy under attacks. For the clean accuracy, we evaluate it on the entire test set.
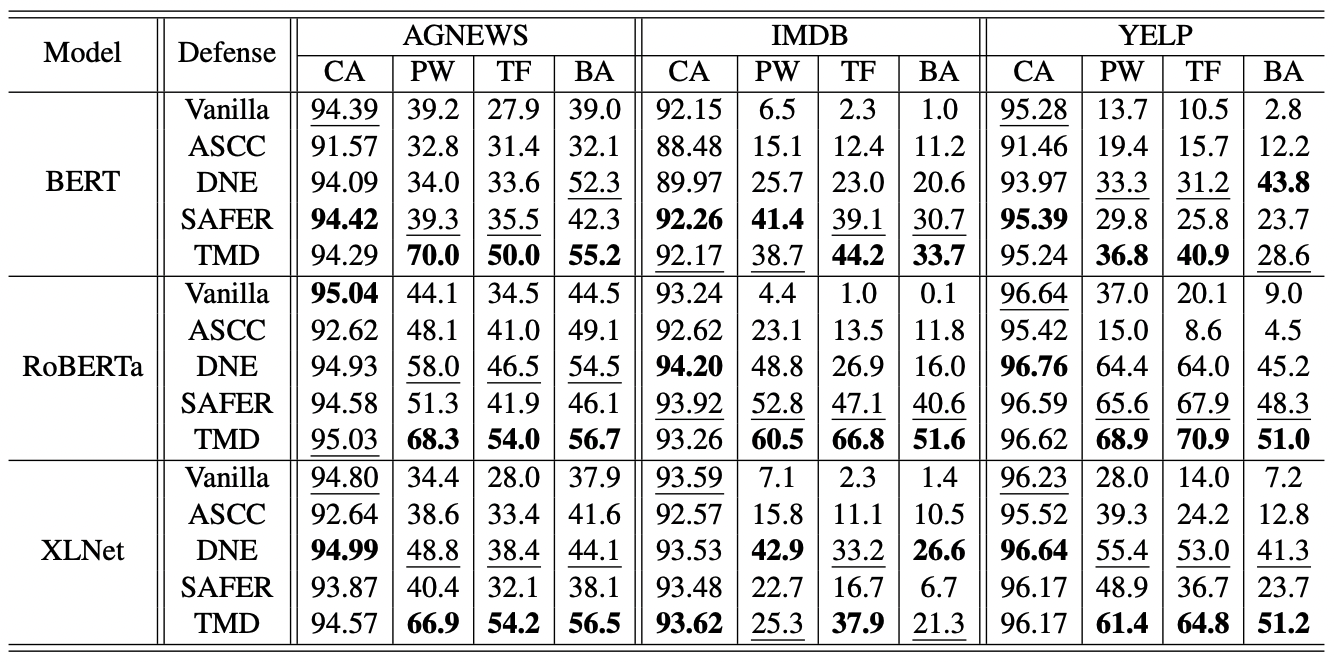
The results for the AGNEWS dataset are shown in the table above. We denote the “Vanilla” method as the original model without any defense mechanism. As we can see from the results, TMD outperforms previous methods under various settings by a large margin. Despite a slight decline in the clean accuracy, TMD achieves state-of-the-art robustness for BERT, RoBERTa, and XLNet with 23.03%, 18.63%, and 25.77% average performance gain over all attacks, respectively.
Interestingly, slightly different trends are found in the IMDB and YELP datasets. First of all, all models are generally more vulnerable to adversarial examples. This could be explained by the long average sentence length in IMDB (313.87 words) and YELP (179.18 words). This value is much larger than the AGNEWS, about 53.17 words. Longer sentences result in less restricted perturbation space for the attacker to perform word-substitution attacks, hence increasing the attack success rate. Regarding robustness, our method outperforms other methods in the majority of cases.
References
[1] Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, and Xipeng Qiu. 2020. BERT-ATTACK: Adversarial Attack Against BERT Using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6193–6202, Online. Association for Computational Linguistics.
[2] Siddhant Garg and Goutham Ramakrishnan. 2020. BAE: BERT-based Adversarial Examples for Text Classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6174–6181, Online. Association for Computational Linguistics.
[3] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2014. Intriguing Properties of Neural Networks. International Conference on Learning Representations (ICLR).
[4] Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. In the 3rd International Conference on Learning Representations (ICLR).
[5] Thomas Tanay and Lewis D. Griffin. 2016. A Boundary Tilting Persepective on the Phenomenon of Adversarial Examples. CoRR.
[6] Justin Gilmer, Luke Metz, Fartash Faghri, Samuel S. Schoenholz, Maithra Raghu, Martin Wattenberg, and Ian J. Goodfellow. 2018. Adversarial Spheres. 6th International Conference on Learning Representations (ICLR).
[7] Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. 2019. Adversarial Examples Are Not Bugs, They Are Features. Advances in Neural Information Processing Systems 32 (NeurIPS).
[8] Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. 2019. Robustness May Be at Odds with Accuracy. 7th International Conference on Learning Representations (ICLR).
[9] David Stutz, Matthias Hein, and Bernt Schiele. 2019. Disentangling Adversarial Robustness and Generalization. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
[10] Adi Shamir, Odelia Melamed, and Oriel BenShmuel. 2021. The Dimpled Manifold Model of Adversarial Examples in Machine Learning. CoRR.
[11] Pouya Samangouei, Maya Kabkab, and Rama Chellappa. 2018. Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models. ICLR.
[12] Bhavani Thuraisingham, David Evans, Tal Malkin, and Dongyan Xu. 2017. MagNet: A Two-Pronged Defense against Adversarial Examples. CCS.
[13] Yang Song, Taesup Kim, Sebastian Nowozin, Stefano Ermon, and Nate Kushman. 2017. PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples. CoRR.
[14] Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. 2016. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. NIPS.
[15] Shuhuai Ren, Yihe Deng, Kun He, and Wanxiang Che. 2019. Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1085–1097, Florence, Italy. Association for Computational Linguistics.
[16] Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. AAAI
[17] Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, and Xipeng Qiu. 2020. BERT-ATTACK: Adversarial Attack Against BERT Using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6193–6202, Online. Association for Computational Linguistics.
[18] Zongyi Li, Jianhan Xu, Jiehang Zeng, Linyang Li, Xiaoqing Zheng, Qi Zhang, Kai-Wei Chang, and Cho-Jui Hsieh. 2021. Searching for an Effective Defender: Benchmarking Defense against Adversarial Word Substitution. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3137–3147, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
[19] Xinshuai Dong and Anh Tuan Luu and Rongrong Ji and Hong Liu. 2021. Towards Robustness Against Natural Language Word Substitutions. ICLR.
[20] Yi Zhou, Xiaoqing Zheng, Cho-Jui Hsieh, Kai-Wei Chang, and Xuanjing Huang. 2021. Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5482–5492, Online. Association for Computational Linguistics.
[21] Mao Ye, Chengyue Gong, and Qiang Liu. 2020. SAFER: A Structure-free Approach for Certified Robustness to Adversarial Word Substitutions. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3465–3475, Online. Association for Computational Linguistics.
 are transformed into continuous representations
are transformed into continuous representations  . An InfoGAN [14] with learnable prior is trained to distinguish between real embeddings
. An InfoGAN [14] with learnable prior is trained to distinguish between real embeddings  versus fake embeddings
versus fake embeddings  to implicitly learn the natural text embedding manifold.
to implicitly learn the natural text embedding manifold. is projected onto the approximated manifold using a sampling-based reconstruction strategy. The reconstructed embedding
is projected onto the approximated manifold using a sampling-based reconstruction strategy. The reconstructed embedding  is fed to the classifier
is fed to the classifier  to produce the final predicted label
to produce the final predicted label  . The colored blobs represent the approximated disjoint submanifolds in the contextualized embedding space.
. The colored blobs represent the approximated disjoint submanifolds in the contextualized embedding space.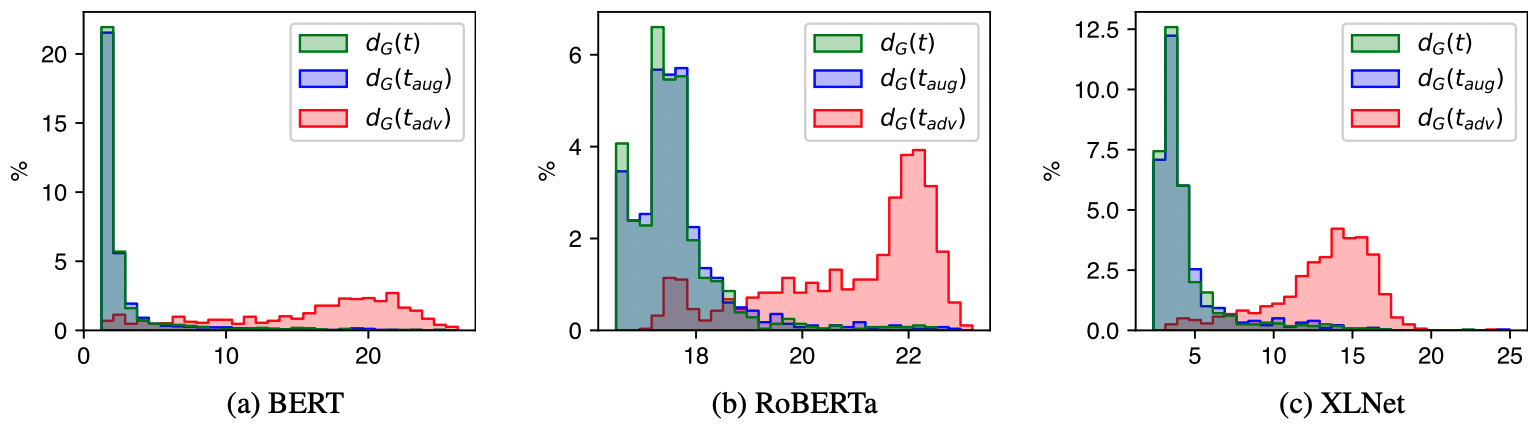
 ,
,  , and
, and  .
. , denoted as
, denoted as  have large values of
have large values of  . Additionally, to ensure that large
. Additionally, to ensure that large  and see if the resulted distribution
and see if the resulted distribution  for AGNEWS, IMDB, and YELP must be
for AGNEWS, IMDB, and YELP must be  ,
,  , and
, and  is set to
is set to  , (3) the minimum semantic similarity\footnote{The semantic similarity between
, (3) the minimum semantic similarity\footnote{The semantic similarity between  is approximated by measuring the cosine similarity between their text embeddings produced from Universal Sentence Encoder \cite{cer-etal-2018-universal}}
is approximated by measuring the cosine similarity between their text embeddings produced from Universal Sentence Encoder \cite{cer-etal-2018-universal}}  between original input
between original input  , and (4) the maximum number of queries to the victim model is
, and (4) the maximum number of queries to the victim model is  , where
, where  is the length of the original input
is the length of the original input