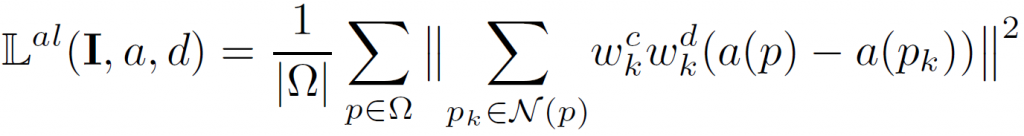Toward Realistic Single-View 3D Object Reconstruction with Unsupervised Learning from Multiple Images
September 20, 2021
Introduction
Recovering the 3D structure of an object from a single image is a challenging task due to its ill-posed nature. One approach is to utilize the plentiful photos of the same object category to learn a strong 3D shape prior for the object. This approach has successfully been demonstrated by a recent work of Wu et al. (2020) (let call it LeSym from now), which obtained impressive 3D reconstruction networks with unsupervised learning. However, their algorithm is only applicable to symmetric objects. In this paper, we eliminate the symmetry requirement with a novel unsupervised algorithm that can learn a 3D reconstruction network from a multi-image dataset. Our algorithm is more general and covers the symmetry-required scenario as a special case. Besides, we employ a novel albedo loss that improves the reconstructed details and realisticity. Our method surpasses the previous work in both quality and robustness, as shown in experiments on datasets of various structures, including single-view, multiview, image-collection, and video sets.
Motivation
LeSym made a break-though in solving this problem with a novel end-to-end trainable deep network. Their network consisted of several modules to regress the image formation’s components, including the object’s 3D shape, texture, viewpoint, and lighting parameters, so that the rendered image was similar to the input.
While showing good initial results, LeSym has a dramatic limitation: it requires the target object to be almost symmetric !!
This motivates us to solve the general cases: both symmetric and non-symmetric objects.
Method
We propose a more general framework, called LeMul, that effectively Learns from Multi-image datasets for more flexible and reliable unsupervised training of 3D reconstruction networks. We revise the mechanism used in LeSym to get LeMul as a more general, effective, and accurate unsupervised 3D reconstruction method. The key idea in our proposal is a multi-image-based unsupervised training. The system overview is illustrated in Figure 1.
Unlike LeSym, we do not require the modeling target to be symmetric. Instead, we assume more than one image for each object in the training data. We run the network modules over each image and enforce shape and albedo consistency. Note that having a single image of a symmetric object is a special case of ours; we can simply use the original and flipped input as two images of each training instance, and the 3D model consistency will enforce the object’s symmetry. Moreover, this configuration can account for many other common scenarios such as multi-view, multiexposure, multi-frame datasets. The multi-image configuration is only needed in training. During inference, the system can output a 3D model from a single input image.
Figure 1: Overview of the proposed system. Our decomposing network consists of four modules to estimate the four intrinsic components albedo, depth, light, view of the input images of the object. Because those input images belong to only 1 object, when we swap the predicted intrinsic components and rerender the image, the results have to be corresponding. The decomposing network is trained to optimize different loss components. Note that we use diffuse shading images to visualize depth maps.
For sharper 3D reconstruction, we apply a regularization on the albedo map to avoid overfitting to pixel intensities. This regularization should guarantee that the albedo is smooth at non-edge pixels while preserving the edges. We implement such regularization by albedo loss terms.
An albedo loss requires three aligned inputs, including an input image I and the corresponding maps for depth d and albedo a. It enforces smoothness on a:
Experiment Results
To evaluate the proposed algorithm, we run experiments on datasets with various capturing settings and data structures: BFM, CelebA, Cat Faces, Multi-PIE, CASIA-WebFace, Youtube Faces (YTF).
Quantitative results:
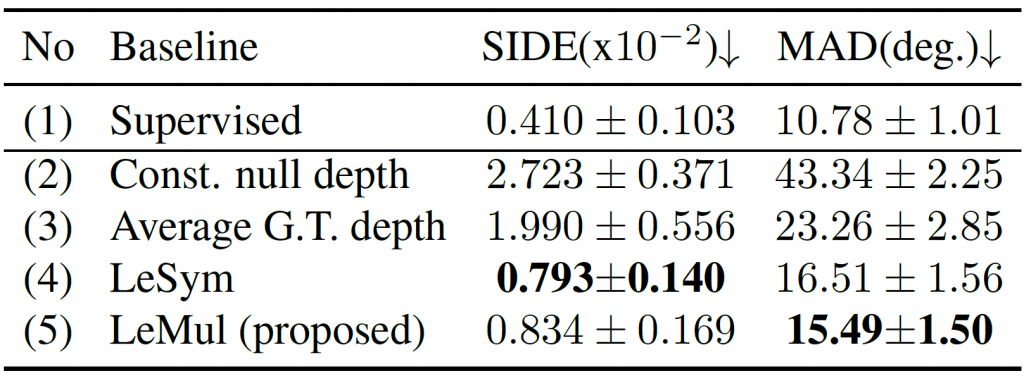
Metrics used: Scale-Invariant Depth Error (SIDE) and Mean Angle Deviation (MAD).
Table 1: BFM results comparison with baselines
Qualitative results:
Conclusion
LeMul shows the state-of-the-art 3D modeling quality in unsupervised learning for single-view 3D object reconstruction. The key insights are to exploit multi-image datasets in training and to employ albedo losses for improved detailed reconstruction. Our method can work on various training datasets ranging from single- and multi-view datasets to image collections and video sets. However, a current limitation of our work is that the images of the target object need to be compatible with the depth-map representation, being primarily at frontal views without self-occlusion. We plan to address this limitation in future work to increase the applicability of our method.
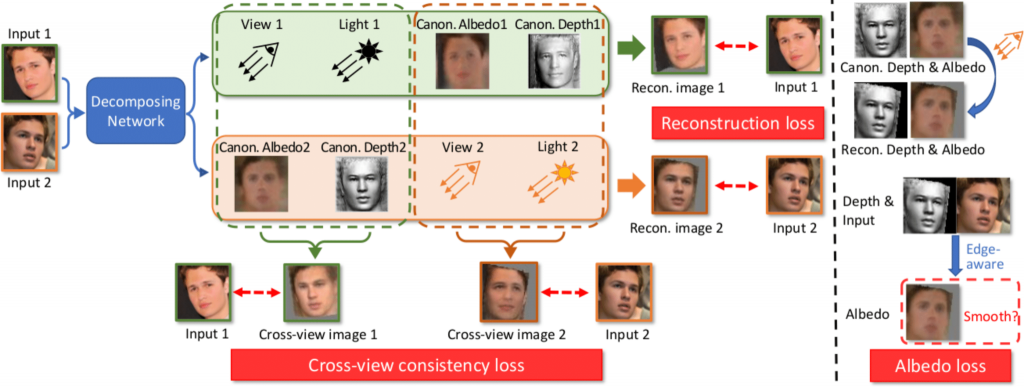 Figure 1: Overview of the proposed system. Our decomposing network consists of four modules to estimate the four intrinsic components albedo, depth, light, view of the input images of the object. Because those input images belong to only 1 object, when we swap the predicted intrinsic components and rerender the image, the results have to be corresponding. The decomposing network is trained to optimize different loss components. Note that we use diffuse shading images to visualize depth maps.
Figure 1: Overview of the proposed system. Our decomposing network consists of four modules to estimate the four intrinsic components albedo, depth, light, view of the input images of the object. Because those input images belong to only 1 object, when we swap the predicted intrinsic components and rerender the image, the results have to be corresponding. The decomposing network is trained to optimize different loss components. Note that we use diffuse shading images to visualize depth maps.