HyperInverter: Improving StyleGAN Inversion via Hypernetwork
June 23, 2022
1. Introduction
Generative Adversarial Networks (GANs) [6] have achieved tremendous progress in recent years. GANs now can be trained to synthesize images at very high resolution, having diverse styles with apparently fewer artifacts. Among them, the Style-based GAN (StyleGAN) family has received a lot of attention from the research community. Going beyond the ability to generate realistic images, the latent space learned by GAN also encodes a diverse set of interpretable semantics, which provide a wonderful tool for conducting image manipulation. To apply such edits to real-world images, the common-used approach is the ”invert first, edit later” pipeline. The first step of this pipeline is GAN Inversion. GAN Inversion is a line of work that aims to encode a real-world image into a latent code in the pre-trained GAN latent space so that the generator can accurately reconstruct the input photo. There are three requirements needed to tackle in solving GAN inversion, which are reconstruction quality, editing ability, and inference time. Unfortunately, existing GAN inversion techniques failed to attain at least one of the three above requirements. Motivated by this issue, we propose a novel GAN inversion method that balances well these key requirements. In this work, we focus mainly on the StyleGAN family.
2. Proposed Method
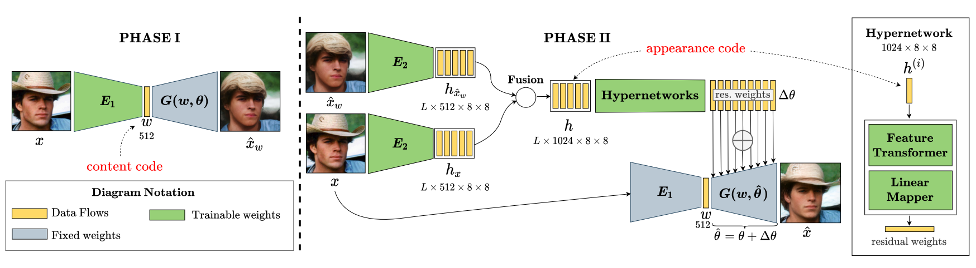
HyperInverter is an entirely encoder-based StyleGAN inversion method that has two consecutive phases:
Phase I: In the first phase, we use an encoder to map the input image to the content code in the native W space for preserving the editing ability. The initial reconstructed image in this phase is quite far from the input image.
Phase II: Therefore, we propose a phase II to improve the reconstruction result further. Specifically, we first extract the appearance code from the input image and the initial reconstructed one. Then, we use the hypernetworks to predict the residual weights from the appearance code to update the generator. The final reconstructed image is obtained by feeding the content code from phase I to the updated generator.
3. Experiments
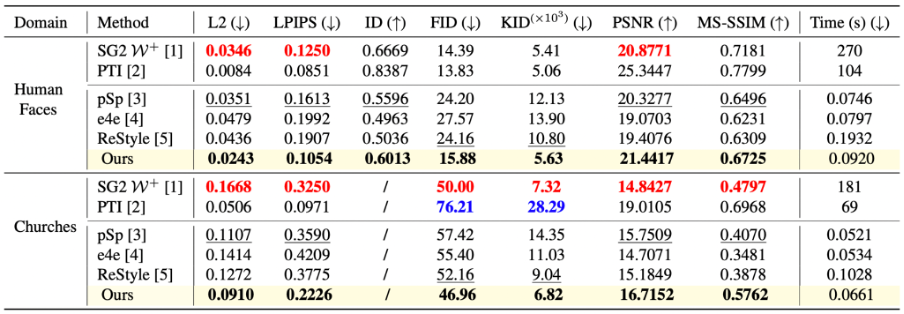
We conducted the experiments on two challenging domains, which are human faces and churches, to verify the effectiveness of our method. We evaluate the method on reconstruction quality, editability, and running time.
3.1. Reconstruction Results
Quantitative Results:
Our method significantly outperforms other encoder-based methods (pSp [3], e4e [4], ReStyle [5]) for reconstruction quality on both domains. Compared to such methods using optimization (and fine-tuning) technique (SG2 W+ [1], PTI [2]), we have comparable performance, but we run very fast in comparison to them.
Qualitative Results:
3.2 Editing Results
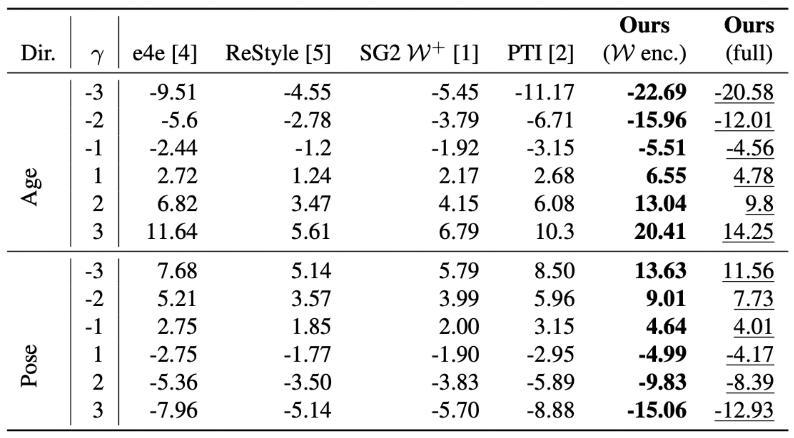
Quantitative Results:
We quantitatively test the effect of the editing operator on the inverted latent code of each inversion method. As can be seen, our Phase I W encoder achieves the most significant editing effects because it works on the highly editable latent code of the native StyleGAN W-space. After Phase II refinement, despite not being as good as the inversion done by Phase I, our method still retains the ability to edit, outperforming all previous methods.
Qualitative Results:
4. Application on Real-world Image Interpolation
Motivated by our inversion method, we also introduce a new approach for real-world image interpolation that interpolates both latent codes and generator weights instead of only interpolating latent codes like previous techniques. The results show that our method not only reconstructed input images with correctly fine-grained details but also provided smooth interpolated images.
5. Conclusion
In our research, we propose a novel StyleGAN inversion technique leveraging the hyper network idea that has high fidelity reconstruction, excellent editability, while running almost in real-time. We also introduce a new method for real-world image interpolation that interpolates both latent codes and generator weights.
References:
[1] Rameen Abdal, Yipeng Qin, and Peter Wonka. Image2StyleGAN: How to embed images into the StyleGAN latent space? In ICCV, 2019.
[2] Daniel Roich, Ron Mokady, Amit H Bermano, and Daniel Cohen-Or. Pivotal tuning for latent-based editing of real images. arXiv preprint arXiv:2106.05744, 2021.
[3] Elad Richardson, Yuval Alaluf, Or Patashnik, Yotam Nitzan, Yaniv Azar, Stav Shapiro, and Daniel Cohen-Or. Encoding in style: a StyleGAN encoder for image-to-image translation. In CVPR, 2021.
[4] Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. Designing an encoder for StyleGAN image manipulation. TOG, 2021.
[5] Yuval Alaluf, Or Patashnik, and Daniel Cohen-Or. ReStyle: A residual-based StyleGAN encoder via iterative refinement. In ICCV, 2021.
[6] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. NeurIPS, 2014.