Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
July 18, 2023
1. Introduction
Any-scale image synthesis is efficient and scalable, but GAN-based solutions rely too heavily on convolutions and hierarchical architecture, causing inconsistency and ‘texture sticking’ when scaling. While INR-based generators are scale-equivariant by design, their large memory footprint and slow inference limit their adoption in real-time or large-scale systems. In this work, we propose Column-Row Entangled Pixel Synthesis (CREPS), a new generative model that is both efficient and scale-equivariant without using any spatial convolutions or coarse-to-fine design. CREPS employs a bi-line representation to save memory and ensure scalability. Experiments on various datasets confirm its ability to produce alias-free images at any resolution while maintaining scale-consistency.
2. Method
2.1. Any-scale image synthesis
Generative Adversarial Networks (GANs) [1] are one of the most widely used structures for image generation and manipulation [2, 3]. Previously, a GAN model could only generate images with a fixed scale and layout as defined in the training dataset. Natural images, however, have different resolutions and unstructured objects in various poses. This has led to interest in creating a generative model that can handle more flexible geometric configurations in the machine-learning community.
In this paper, we are interested in the task of arbitrary-scale image synthesis where a single generator can effortlessly synthesize images at many different scales while stronglypreserving detail consistency. Such a model enables synthesizing a high-resolution image from a lower-resolution training dataset or allows geometric interactions like zooming in and out. Despite promising results, previous works on this topic, such as AnyresGAN [4] and ScaleParty [5], show strong inconsistency when scaling the output resolution.
Previous any-scale image synthesis networks, including AnyresGAN [4] and ScaleParty [5], produce inconsistent image details when changing the output scale (see zoomed-in patches). In contrast, our proposed network can produce the same details but sharper when increasing the scale.
2.2. Revisit existing any-scale GANs
AnyresGAN [4] is a notable work that supports any-scale image synthesis. While having good photo-realism, AnyresGAN produces different image details at different scales. This can be explained by the fact that AnyresGAN, similar to most other GAN-based works, relies on spatial convolutions, such as 2D convolution with kernel size 3×3 and upsample layers. When changing the output resolution, the neighbor pixels at each location change, greatly varying the output of this spatial-convolution-based network.
On the other hand, an INR-based GAN, called CIPS, keeps the output image’s details nearly the same regardless of resolution, thanks to its spatial-free building operators. CIPS, however, is very computationally expensive making such a model inapplicable to use for learning fine details from high-resolution datasets.
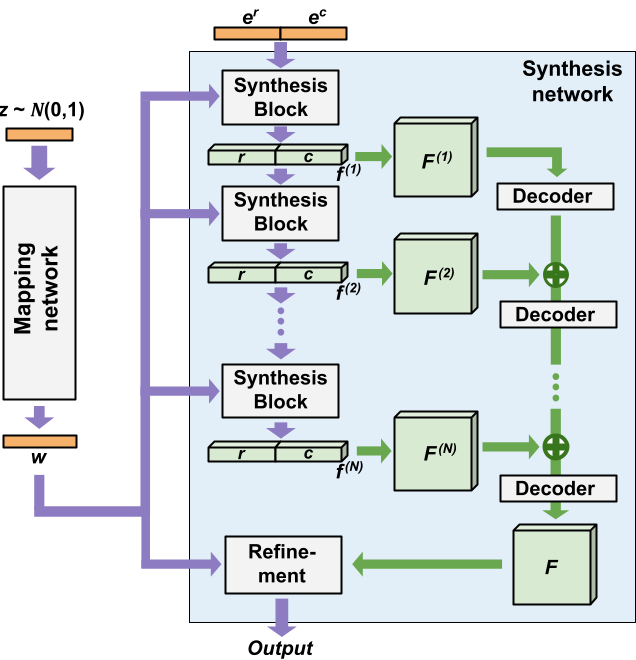
Based on the above observations, we implement CREPS without any spatial convolutions or coarse-to-fine design. Starting with StyleGAN2 [6], which consists of a mapping network and a generator, we remove all upsampling operators and replace all spatial convolutions with 1 × 1 convolutions, which are equivalent to pixel-wise fully-connected layers. Next, we replace the constant in the first synthesis block with Fourier encodings of the input coordinate row and column er and ec. In next sections, we will discuss our bi-line representations and layer-wise feature composition which are the key contributions to make our model efficient and high-quality.
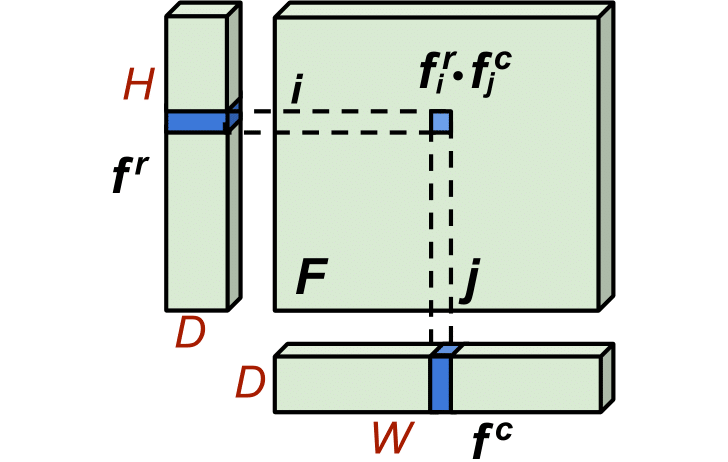
2.3. Thick bi-line representation
Inspired by the tri-plane representation in [7], we propose to decompose each feature with 2D spatial dimensions into a column and a row embedding for a memory-efficient representation. Let us denote the feature map as , with H and W as the height and width, respectively. We can decompose F to a row embedding and a column embedding , which can compose back into F via dot product. We call this representation “bi-line”, which significantly reduces the memory usage and computation cost in case D << min(H, W). In the simplest form, and can be 1D vectors with D=1. However, we found that such simple representation had a limited capacity. To enrich its representation power, we “thicken” the embeddings by setting D as a moderate value.
2.4. Layer-wise feature composition
Initially, our design performs feature composition only once near the end of the image synthesis process; thus, the model power was bounded by the capacity of the thick bi-line representation. Instead, we revise our solution by employing a layer-wise feature composition scheme. We add asymmetry to the feature map fusion process: the feature maps at earlier layers are processed “deeper” than those at later layers. To do so, we introduce at each layer with a narrow decoder consisting of fully-connected layers with Leaky-RELU activations. The figure below illustrates our proposed network structure and the feature composition scheme.
3. Experiments
3.1. Image Generation
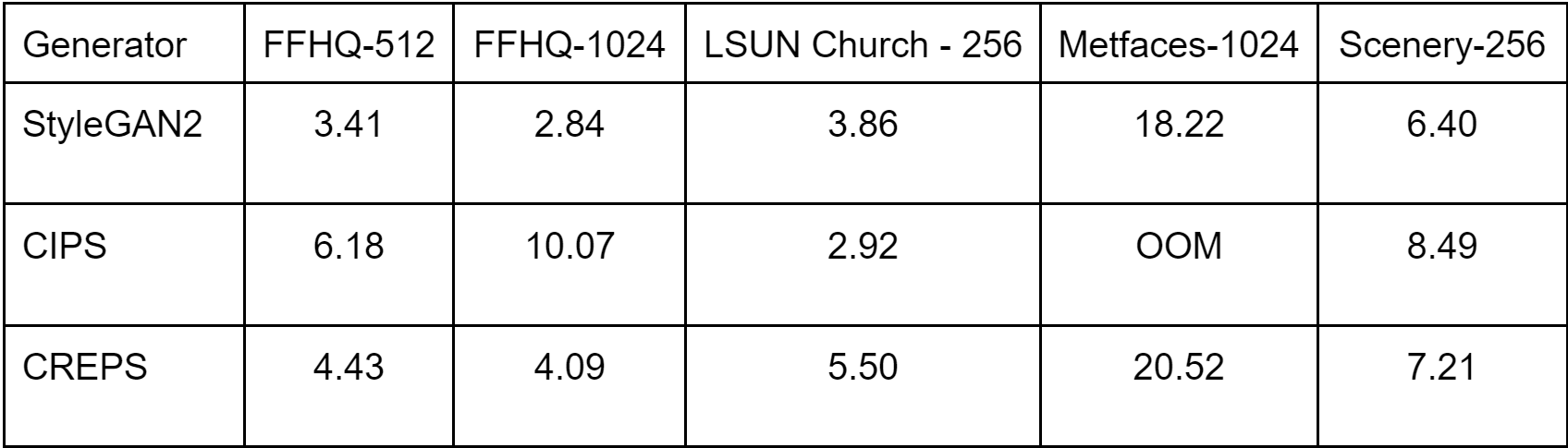
The below table compares the quality of images generated by our CREPS models with the standard spatial-convolution-based StyleGAN2 and the scale-consistent image generator CIPS, using the Frechet Inception Distance (FID) score, where the lower is the better.
As shown in the table, CREPS achieve competitive results for all datasets except LSUN Church at resolution 256×256, while StyleGAN produces the best. It is worth noting that CIPS ran out of memory (OOM) when training normally at resolution 1024 and the weight trained on FFHQ-1024 was possible only by under-parameterizing the network.
Below figure provides some samples synthesized by our networks on the benchmark datasets. As can be seen, CREPS produces highly realistic images in all cases.
Sample images with our models trained on FFHQ (upper-left), LSUN-Church (upper-right), MetFace (bottom-left), and Flickr-Scenery (bottom-right).
3.2. Image scaling consistency
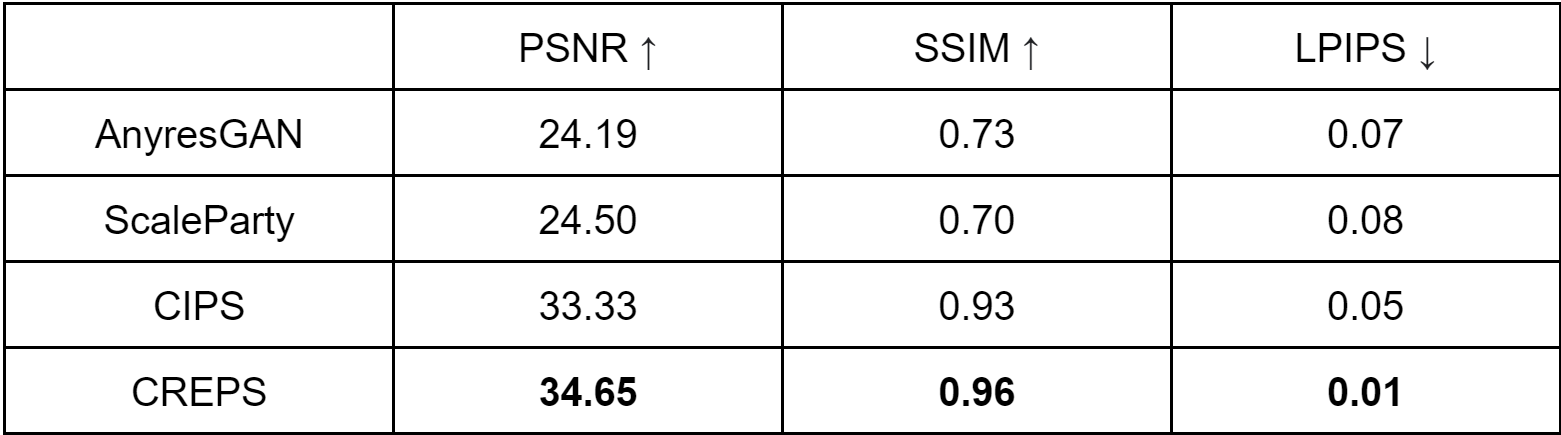
In this section, we evaluate the scale consistency of images produced by CREPS and other methods, including AnyresGAN [4], ScaleParty [5], and CIPS [8]. We run this experiment using models trained on the FFHQ dataset. For each model, we first randomly generate 10k images at resolution 256 × 256 (first set). We then generate images with the same latent codes but at resolution 512 × 512 and downsample them to 256×256 (second set). The images in two sets are expected to be the same. Hence, we can compare two sets, with standard metrics such as PSNR, SSIM, and LPIPS, to measure each model’s scale equivariance in the table below. Best scores are in bold.
We visualize some results in the figure below. As can be seen, it is clear that CREPS achieves the best scale consistency, while convolution-based models like ScaleParty and AnyresGAN perform poorly.
Qualitative results for the scale consistency experiment. For each method, we provide a sample generated 256×256 image (top) and the magnified (×10) residual map between it and the 512 × 512 rescaled version (bottom).
3.3. Ablation Study
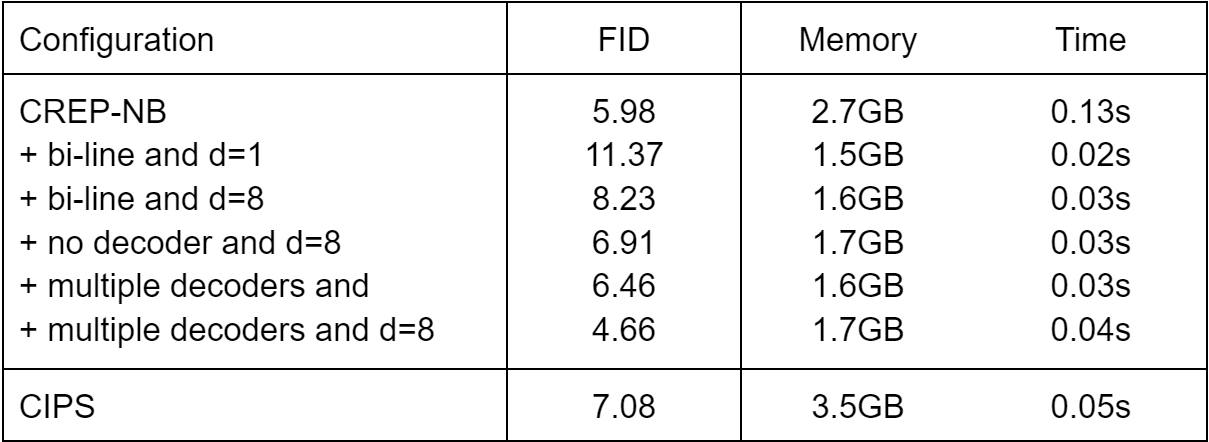
To better understand our proposed techniques, we analyze the effect of different parts of CREPS on the FFHQ datasets. We first consider a no-bi-line version of CREPS as a baseline (referred to as CREPS-NB). We then apply bi-line decomposition and add multiple decoders for layer-wise feature composition. These models are trained and evaluated on 128 x 128 resolution.
As the results in the table below show, CIPS performs worst in all three aspects compared with most of our models. Simply adding the bi-line reduces the memory costs, but the FID score worsens. However, multiple decoders can boost the image quality. These observations prove the importance of our proposed techniques. Remarkably, the decoders cause only small increases in memory and time due to their narrow width compared with other layers.
4. Exploring CREPS’ Geometry Invariance
By setting the coordinate grid appropriately, our generator is capable of synthesizing with various geometric configurations such as translation, zooming in/out, rotation or distortion.
5. Limitation
Being a fully-connected generator, CREPS shares the same limitation with other similar work, which is the lack of spatial bias since each pixel is independently generated. Hence, some spatial-related artifacts occasionally occur in our generated images. A potential cause is the sine activation at the beginning, producing repeating patterns and vertical symmetry of the output. We also note that some samples contain a noticeable blob that is completely out-of-domain. We hypothesize that the root cause can be the missing spatial guidance from neighboring pixels and the effect of Leaky-RELU activations which strengthens the isolation of some pixel regions.
Samples of the most common kinds of artifacts on different datasets. They are best described as repeating/wavy patterns, vertical symmetry, and glowing blobs. Left-most image is cropped and zoomed-in from a full-face image.
6. Conclusion
In this paper, we present a new architecture named CREPS, a cost-effective and scale-equivariant generator that can synthesize images with any target resolution. Our key contributions are an INR-based design, a thick bi-line representation, and a layer-wise feature composition scheme. While being more memory-efficient, our CREPS models can produce highly realistic images and surpass the INR-based model CIPS in most cases. CREPS also offers the best scale consistency by keeping image details unchanged when varying the output resolution. We conducted several experiments to explore some attractive properties of this fully-connected generator and discussed CREPS’s applications in various scenarios. Future development of our approach can be eliminating artifacts mentioned in Section 5 and further improving the quality of our samples.
7. References
[1] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks, 2014
[2] A.H. Bermano, R. Gal, Y. Alaluf, R. Mokady, Y. Nitzan, O. Tov, O. Patashnik, and D. Cohen-Or. State-of-the-art in the architecture, methods and applications of stylegan. Computer Graphics Forum, 41(2):591–611, 2022.
[3] Weihao Xia, Yulun Zhang, Yujiu Yang, Jing-Hao Xue, Bolei Zhou, and Ming-Hsuan Yang.
Gan inversion: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 2022.
[4] Lucy Chai, Michael Gharbi, Eli Shechtman, Phillip Isola, and Richard Zhang. Any-resolution training for high-resolution image synthesis. In European Conference on Computer Vision (ECCV), 2022
[5] Evangelos Ntavelis, Mohamad Shahbazi, Iason Kastanis, Radu Timofte, Martin Danelljan, and Luc Van Gool. Arbitrary-scale image synthesis. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
[6] Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila. Analyzing and Improving the Image Quality of StyleGAN. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
[7] Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. Efficient Geometry-aware 3D Generative Adversarial Networks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
[8] Ivan Anokhin, Kirill Demochkin, Taras Khakhulin, Gleb Sterkin, Victor Lempitsky, and Denis Korzhenkov. Image generators with conditionally-independent pixel synthesis. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.