XPhoneBERT: A Pre-trained Multilingual Model for Phoneme Representations for Text-to-Speech
July 11, 2023
Motivations:
Advancements in neural TTS technology have led to significant improvements in producing natural-sounding speech. Some works incorporate contextualized word embeddings generated by the pre-trained BERT into their standard encoder. Recent works also confirm that pre-trained models for phoneme representations help improve advanced TTS systems.
However, the success of these pre-trained language models has been limited to the English language only. It is worth exploring pre-trained models for phoneme representations in languages other than English.
How we handle:
To fill the gap, we train the first large-scale multilingual language model for phoneme representations, using a pre-training corpus of 330M phonemic description sentences from nearly 100 languages and locales. Our model is trained based on the RoBERTa pre-training approach, using the BERT-base model configuration. We train for 20 epochs in about 18 days.
How we evaluate:
For English, we use the benchmark dataset LJSpeech consisting of 13,100 audio clips of a single speaker with a total duration of about 24 hours. For Vietnamese, we randomly sample 12,300 different medium-length sentences from the PhoBERT pre-training news data and hire a professional speaker to read each sentence, resulting in a total duration of 18 hours.
We evaluate the performance of TTS models using subjective and objective metrics. For subjective evaluation of the naturalness, for each language, we randomly select 50 ground truth test audios and their text transcription to measure the Mean Opinion Score (MOS). For objective evaluations, we compute two metrics of the mel-cesptrum distance (MCD) and the F0 root mean square error (RMSE F0; cent).
We also randomly select and use 5% of the training audio clips to show our model’s effectiveness at producing fairly high-quality synthesized speech with limited training data.
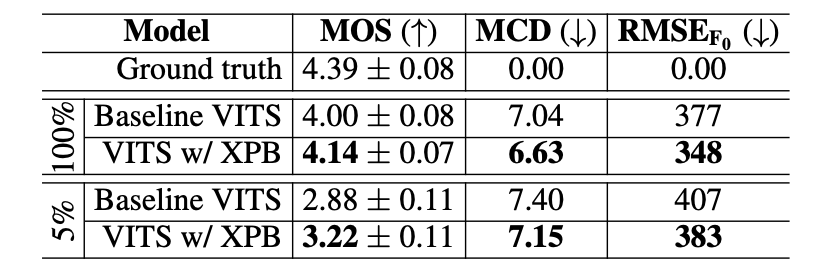
Table 1: Obtained results on the English test set
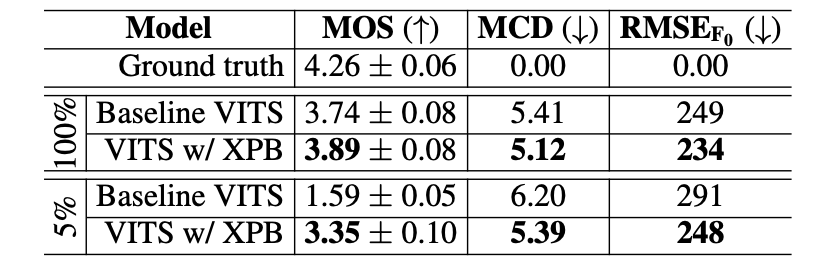
Table 2: Obtained results on the Vietnamese test set
From Table 1 and 2, we find that our XPhoneBERT helps improve the performance of the baseline VITS on all three evaluation metrics for both English and Vietnamese in both experimental settings. For the first setting of using the whole TTS training set for training, the MOS score significantly increases from 4.00 to 4.14 (+0.14 absolute improvement) for English and from 3.74 to 3.89 (+0.15) for Vietnamese. When it comes to the second setting of using limited training data, XPhoneBERT helps produce larger absolute MOS improvements than those for the first setting. That is, MOS increases from 2.88 to 3.22 (+0.34) for English and especially from 1.59 to 3.35 (+1.76) for Vietnamese, clearly showing the effectiveness of XPhoneBERT.
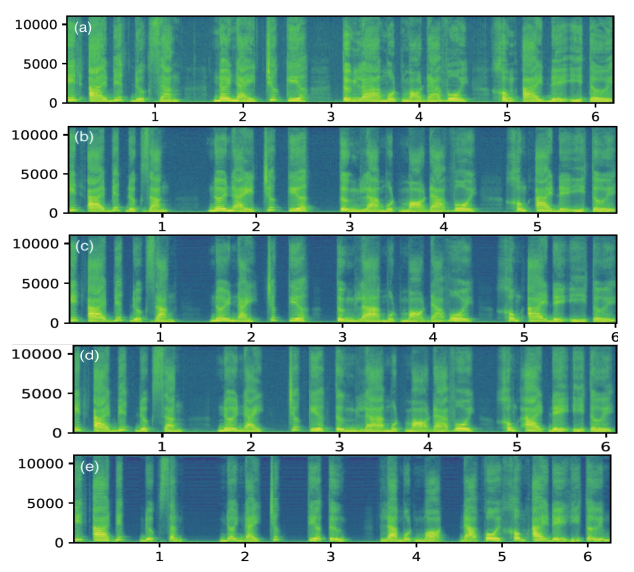
We also visualize the spectrograms of synthesized and ground truth speeches for a Vietnamese text transcription in Figure 1, illustrating that XPhoneBERT helps improve the spectral details of the baseline VITS’s output.
Figure 1: Spectrograms visualization by different models. The text of the speech is “Ít ai biết được rằng nơi này trước kia từng là một mỏ đá vôi không ai để ý tới” (Little is known that this place was once a limestone quarry that no one paid any attention to). (a): Ground truth; (b): VITS with XPhoneBERT, under the first experimental setting; (c): VITS with XPhoneBERT, under the second experimental setting; (d): Original VITS, under the first setting; (e): Original VITS, under the second setting.
Why it matters:
We have presented the first large-scale multilingual language model XPhoneBERT pre-trained for phoneme representations. We demonstrate the usefulness of XPhoneBERT by showing that using XPhoneBERT as an input phoneme encoder improves the quality of the speech synthesized by a strong neural TTS baseline. XPhoneBERT also helps produce fairly high-quality speech when the training data is limited. We publicly release XPhoneBERT and hope that it can foster future speech synthesis research and applications for nearly 100 languages and locales.