A Self-enhancement Multitask Framework for Unsupervised Aspect Category Detection
March 22, 2024
1. Problem
Aspect Category Detection (ACD), Aspect Term Extraction (ATE), and Aspect Term Polarity (ATP) are three challenging sub-tasks of Aspect Based Sentiment Analysis, which aim to identify the aspect categories discussed (e.i., FOOD), all aspect terms presented (e.i., ‘fish’, ‘rolls’), and determine the polarity of each aspect term (e.i., ‘positive’,‘negative’) in each sentence, respectively.
2. Prior works and their limitations
Unsupervised ACD has mainly been tackled by clustering sentences and manually mapping these clusters to corresponding golden aspects using top representative words (He et al., 2017; Luo et al., 2019; Tulkens and van Cranenburgh, 2020; Shi et al., 2021). However, this approach faces a major problem with the mapping process, requiring manual labeling and a strategy to resolve aspect label inconsistency within the same cluster.
Recent works have introduced using seed words to tackle this problem (Karamanolakis et al., 2019; Nguyen et al., 2021; Huang et al., 2020). These works direct their attention to learning the embedding space for sentences and seed words to establish similarities between sentences and aspects. As such, aspect representations are limited by a fixed small number of the initial seed words. (Li et al., 2022) is one of the few works that aims to expand the seed word set from the vocabulary of a pretrained model. However, there is overlap among the additional seed words across different aspects, resulting in reduced discriminability between the aspects.
Another challenge for the unsupervised ACD task is the presence of noise, which comes from out-of-domain sentences and incorrect pseudo labels. This occurs because data is often collected from various sources, and the pseudo labels are usually generated using a greedy strategy. Current methods handle noisy sentences by either treating them as having a GENERAL aspect (He et al., 2017; Shi et al., 2021) or forcing them to have one of the desired aspects (Tulkens and van Cranenburgh, 2020; Huang et al., 2020; Nguyen et al., 2021). To address incorrect pseudo labels, (Huang et al., 2020; Nguyen et al., 2021) attempt to assign lower weights to uncertain pseudo-labels. However, these approaches might still hinder the performance of the model as models are learned from a large amount of noisy data.
3. Method
Our framework addresses three tasks for which no annotated data is available: Aspect Category Detection (ACD), Aspect Term Extraction (ATE), and Aspect Term Polarity (ATP). ACD involves assigning a given text to one of K pre-defined aspects of interest. ATE extracts OTEs in the text. ATP assigns a sentiment to each OTE. Note that, during training, we do not use any human-annotated samples, but rather rely on a small set of seed words to provide supervision signals.
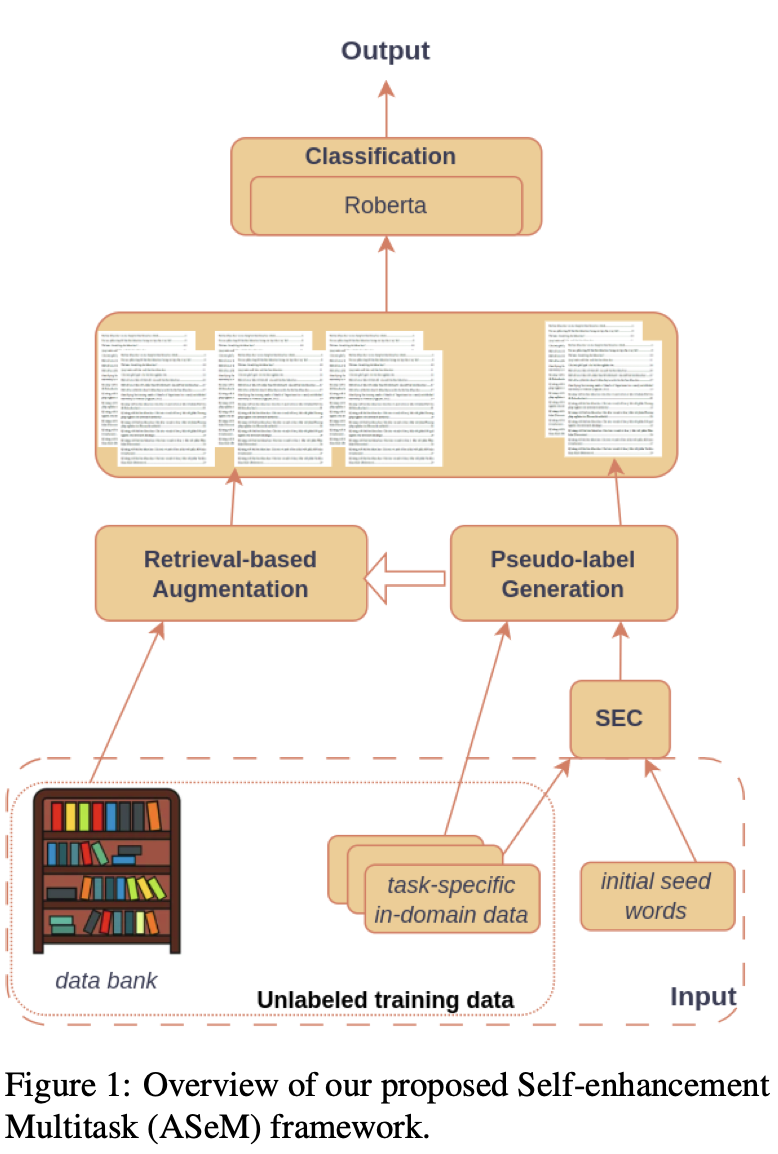
Our framework called ASeM (short for A Self-enhancement Mutitask Framework), consists of three key components: (i) Pseudo-label generation, (ii) Retrieval-based data augmentation, and (iii) Classification. Figure 1 presents an overview of the framework. Initially, we extract a small subset of the training data to serve as the task-specific in-domain data. Based on the quality of the initial seed words in this dataset, we utilize SEC to expand the set of seed words in order to enhance its quality. By feeding the task-specific in-domain data and enhanced seed words to the pseudo-label generation, we obtain high-quality pseudo labels for the task-specific in-domain data. Then, we leverage the retrieval-based augmentation to enhance the number of training samples from the data bank (the remaining part of the training data), based on our prior knowledge of the target task (seed words, task specific in-domain data with high-quality pseudo labels). To this end, the high-quality pseudo labels and augmented data are passed through a multitask classifier to predict the task outputs.
4. Experiments
4.1. Datasets
Restaurant/Laptop containing reviews about restaurant/laptop (Huang et al., 2020). We use the training dataset as the sentence bank and the SemEval training set (Pontiki et al., 2015, 2016) as task-specific in-domain data and dev set with a ratio of 0.85. The test set is taken from SemEval test set (Pontiki et al., 2015, 2016). Restaurant contains labeled data for all three tasks, where ACD has five aspect category types and ATP has two polarity types. Laptop only has labels for ACD with eight aspect category types, and Sentence-level ATP with two polarity types. For initial seed words, follow- ing (Huang et al., 2020; Nguyen et al., 2021) we have five manual seed words and five automatic seed words for each label of ACD and Sentence-level ATP.
CitySearch containing reviews about restaurants (Ganu et al., 2009), in which the test set only contains labeled ACD data with three aspect category types. Similarly to Restaurant/Laptop, we use SemEval training set (Pontiki et al., 2014, 2015, 2016) as task-specific in-domain data and dev set with a ratio of 0.85. For seed words, similar to (Tulkens and van Cranenburgh, 2020), for Citysearch we use the aspect label words food, ambience, staff as seed words.
4.2. Baselines
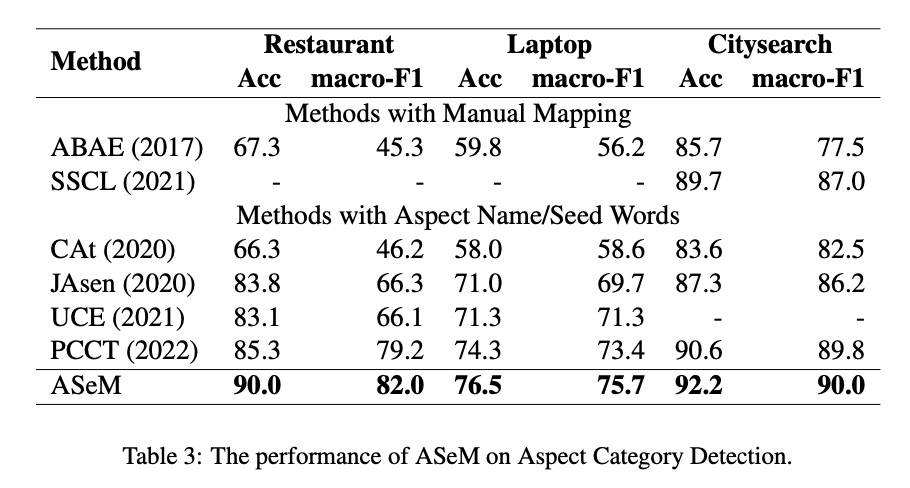
We compare ours to recent unsupervised ACD methods, including ABAE (He et al., 2017), CAt (Tulkens and van Cranenburgh, 2020), JASen (Huang et al., 2020), SSCL (Shi et al., 2021), UCE (Nguyen et al., 2021), and PCCT (Li et al., 2022). Currently, PCCT is state-of-the-art on all three datasets.
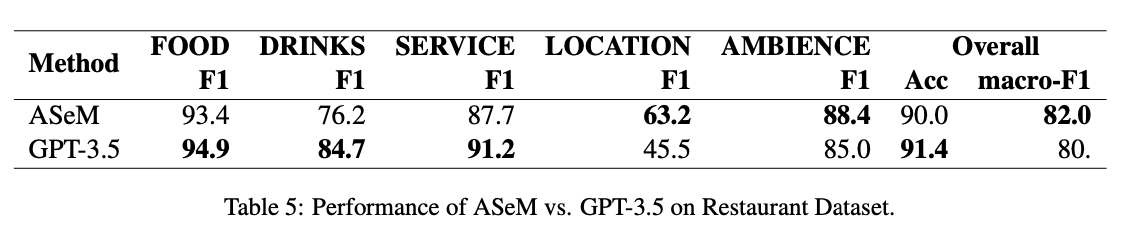
Concerning the utilization of seed words to guide inference for larger LLMs, such as generative models like GPT-3.5, we conducted an experiment involving model gpt-3.5-turbo (from OpenAI) to infer aspect labels.
5. Evaluation
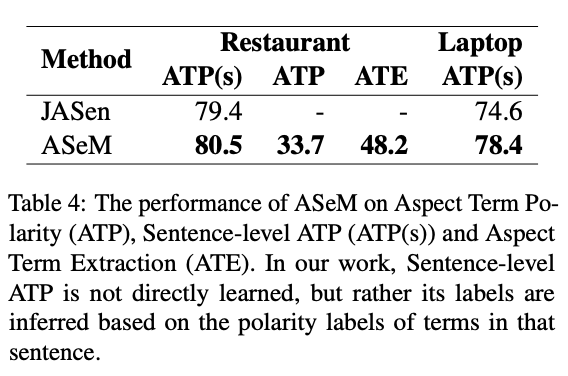
First, we report the results of our framework on the ACD task in Table 3, and ATP and ATE in Table 4. During training, we utilize multitask learning for ACD, ATP, and ATE. However, due to limited labeled tasks in the test datasets, we only evaluate tasks with labels. Further details can be found in subsection 4.1. The results of prior methods were collected from the respective works. For initial seed words, we employ the seed words recommended by (Huang et al., 2020) for the Restaurant and Laptop, as well as the seed words suggested by (Tulkens and van Cranenburgh, 2020) for CitySearch. Following (Huang et al., 2020), we evaluate the ACD performance by accuracy and macro-F1. Similarly, we evaluate ATP(s) (shorted for Sentence-level ATP) and ATP (shorted for Term- level ATP) by accuracy and macro-F1; and ATE by F1-score. As can be seen, despite using less human supervision compared to manual mapping-based methods, seed word-based methods yield competitive results.
Overall, ASeM demonstrates state-of-the-art performance in Aspect Category Detection across various domains, providing clear evidence of the effectiveness of the proposed framework.
6. Conclusion
In this work, we propose a novel framework for ACD that achieves three main goals: (1) enhancing aspect understanding and reducing reliance on initial seed words, (2) effectively handling noise in the training data, and (3) self-boosting supervised signals through multitask-learning three unsupervised tasks (ACD, ATE, ATP) to improve performance. The experimental results demonstrate that our model outperforms the baselines and achieves state-of-the-art performance on three benchmark datasets. In the future, we plan to extend our framework to address other unsupervised problems.
7. Limitations
Although our experiments have proven the effectiveness of our proposed method, there are still some limitations that can be improved in future work. First, our process of assigning keywords to their relevant aspects is not entirely accurate. Future work may explore alternatives to make this process more precise. Second, through the analysis of the results, we notice that our framework predicts the aspect categories of sentences with implicit aspect terms less accurately than sentences with explicit aspect terms. This is because we prioritize the presence of aspect terms in sentences when predicting their aspect categories, which can be seen in the pseudo-label generation. However, sentences with implicit aspect terms do not contain aspect terms, or even contain terms of other aspects, leading to incorrect predictions. For example, the only beverage we did receive was water in dirty glasses was predicted as DRINKS instead of the golden aspect label SERVICE. Future works may focus more on the context of sentences to make better predictions for sentences with implicit aspect terms.