Continual Relation Extraction via Sequential Multi-Task Learning
March 22, 2024
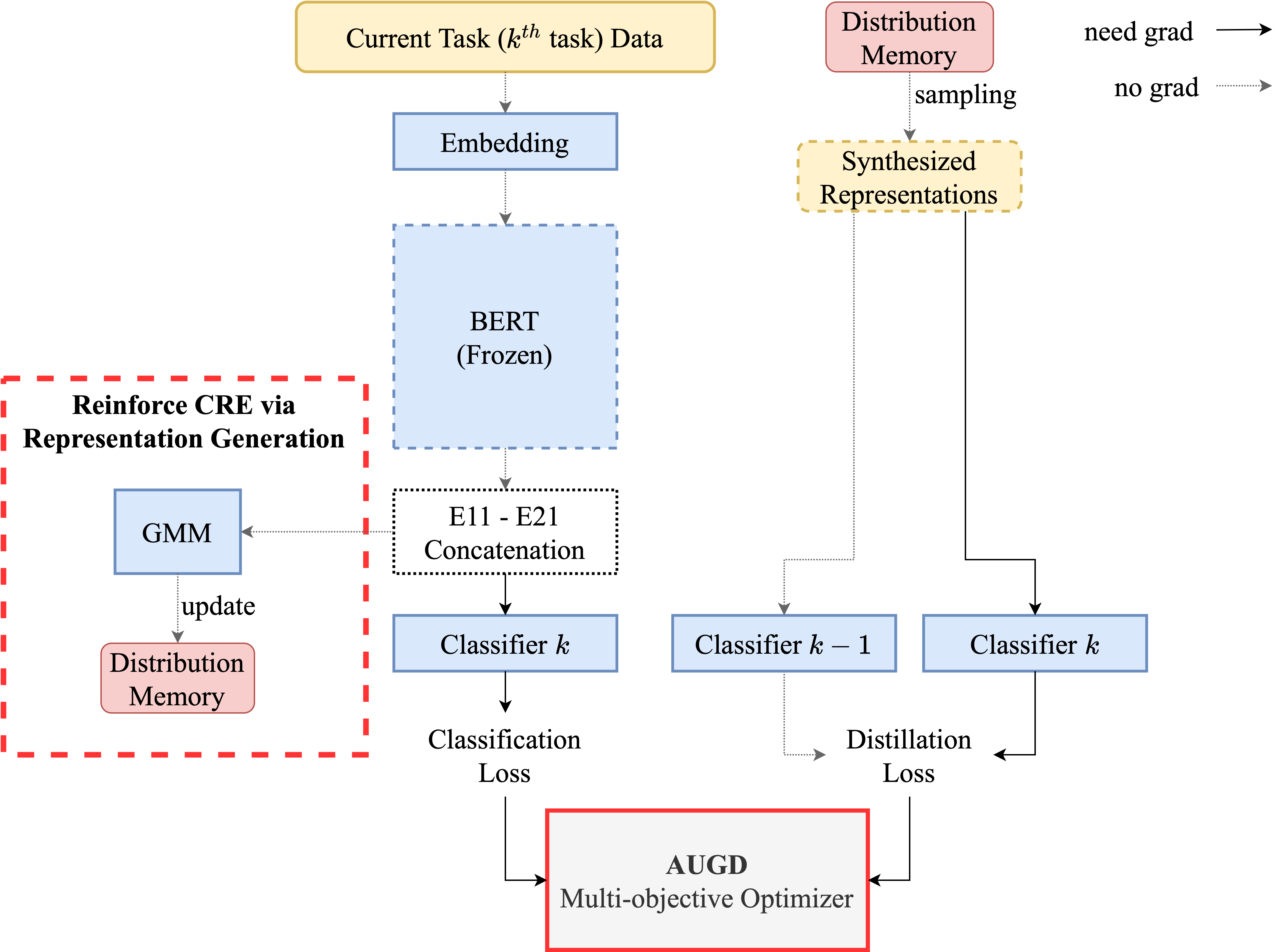
Figure 1: Overview of CREST
Motivations
In Natural Language Processing, Relation Extraction is the task of classifying the semantic relationships between entities/events in text into predefined relation types. Nonetheless, conventional relation extraction encounters challenges in dynamic environments characterized by a continuously expanding set of relations. This realization has prompted the development of Continual Relation Extraction models, which recognize the ever-changing nature of information in practical settings. In this paper, we present a novel CRE approach named CREST.
Problem formulation
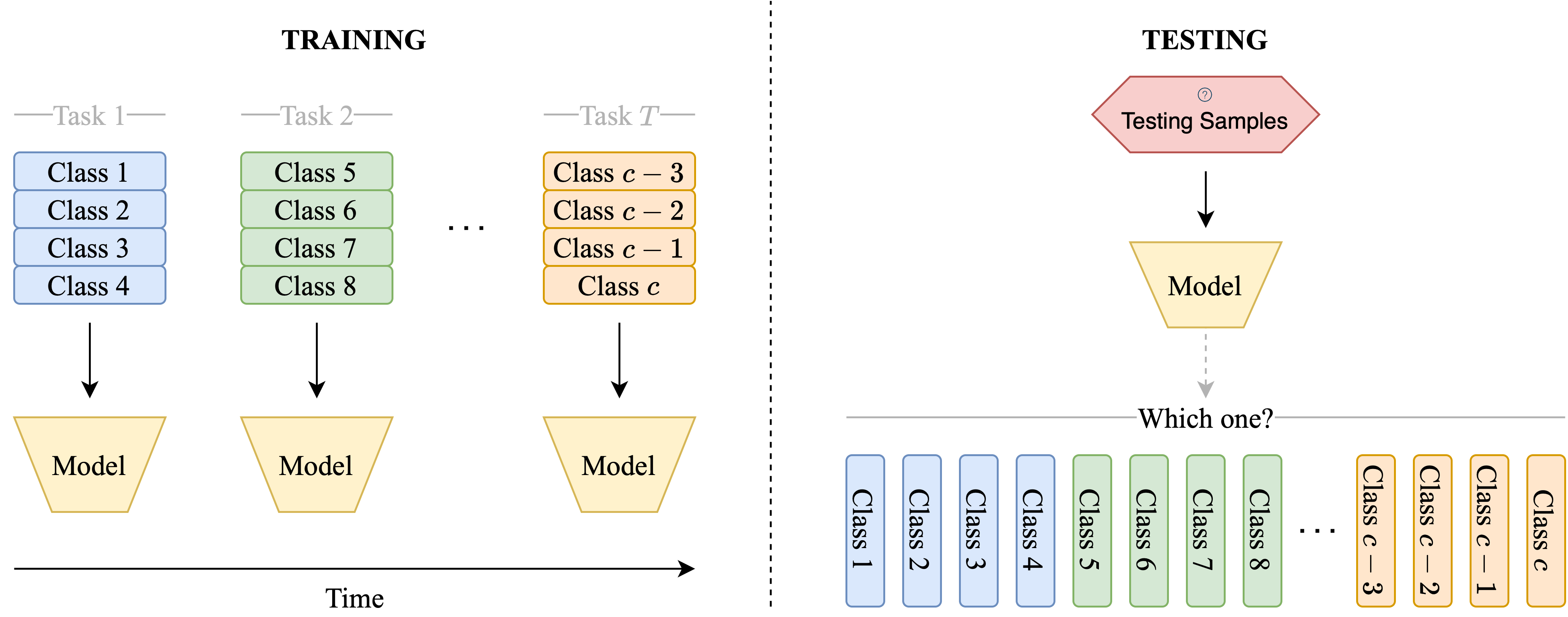
Figure 2: Training and testing setting of CRE
Continual Relation Extraction involves training a model, sequentially, on a series of tasks, each with its own, non-overlapping training set and corresponding relation set. For ease of understanding, each task can be perceived as a conventional relation extraction problem. The aim of Continual Relation Extraction is to develop a model capable of acquiring knowledge from new tasks while maintaining its competence in previously encountered tasks.
Prior works and their limitations
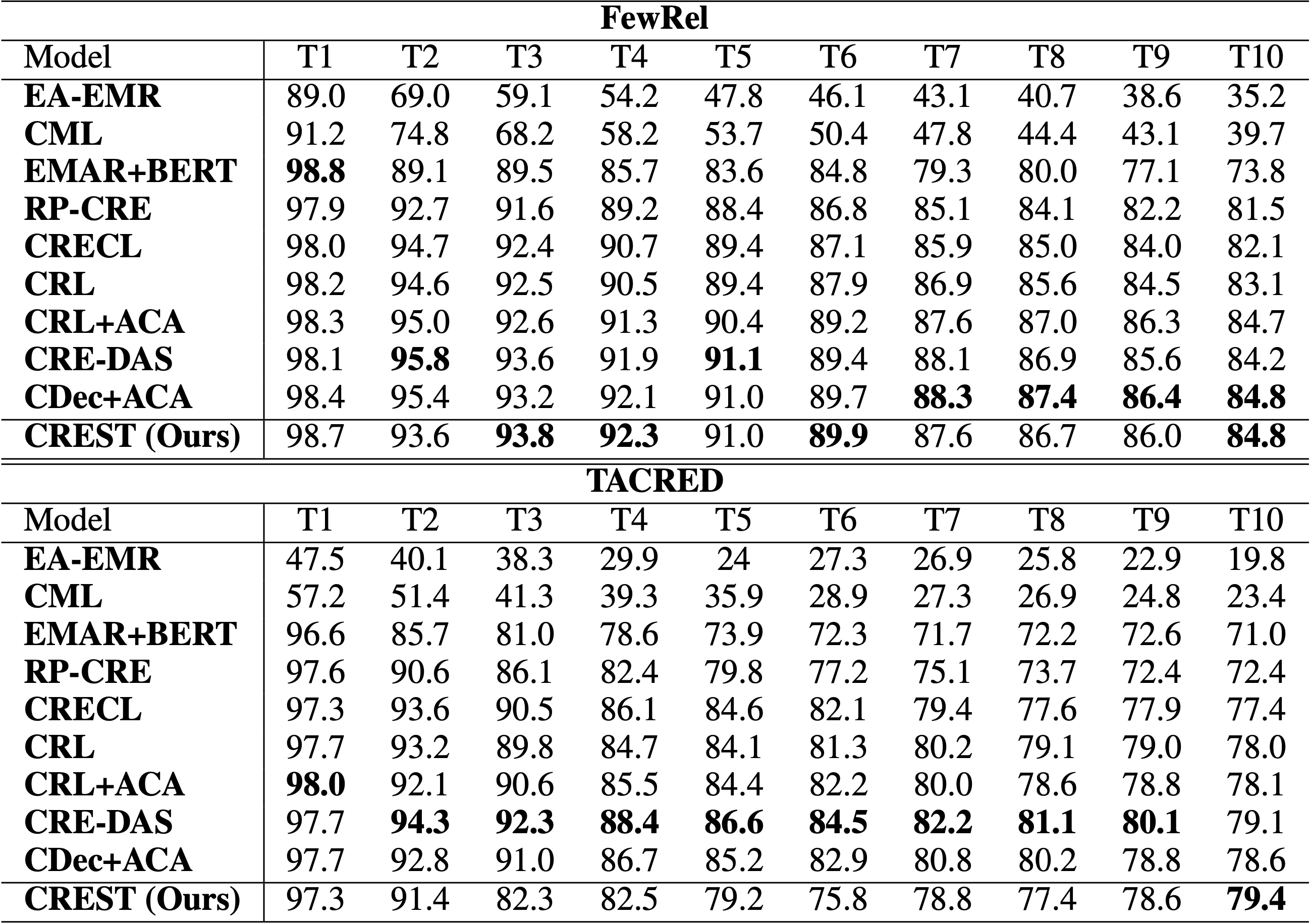
Previous CRE approaches [1, 2, 3] have achieved impressive results using memory-based techniques. These methods retain a fraction of learned data in a small memory buffer, allowing the model to reinforce its past knowledge while learning new relations. Despite their success, state-of-the-art CRE methods persist two lingering issues:
The first issue is their reliance on a memory buffer (Issue No. 1). In light of the diverse potential applications of CRE, many of which might involve highly confidential data, there are significant concerns regarding storing data in the long term while maintaining stringent privacy standards.
Another problem that arises from such methods is the task of handling multiple objectives during replay (Issue No. 2). For example, Hu et al.’s [1] method involves InfoNCE contrastive loss [4] and contrastive margin loss, while Zhao et al.’s [2] approach involves supervised contrastive loss and distillation loss. These methods over-simplistically aggregate these losses by weighted summation, hence overlooking the inherent, complicated trade-offs between the objectives.
Solving Issue No. 1
A notable obstacle in replay-based CRE, and also in replay-based Continual Learning in general, arises from the limited size of the replay buffer in contrast to the continuous accumulation of data. This situation, apart from generating concerns about compromising privacy, introduces the risk of model overfitting to small memory buffers, thereby weakening the efficiency of replaying.
To address these issues and diversify memory buffers, generative models prove effective by synthesizing representations for each relation type. Since we keep the BERT encoder frozen during training, which eliminates any changes to the representations after each updating step of the model, we can directly fit the generative model to the relation representations of all the data. This can be much more practical and feasible than fitting the model to the original embedding matrices of the text instances.
After training the model on task , for each relation type , we use a Gaussian Mixture Model (GMM) to learn the underlying data distribution of the relation representations corresponding to the data from that specific label and store this distribution for future sampling. In the next task (), for each relation type , we use its corresponding learnt distribution to sample synthetic relation representations:
where is the number of GMM components; , and are the mixing coefficient, mean and diagonal covariance of Gaussian distribution, respectively.
The generated set will facilitate the model in reinforcing its previous knowledge via knowledge distillation. The distillation loss facilitates continual learning by transferring knowledge from previous tasks to the current task, enabling the model to retain previously learned information and avoid catastrophic forgetting.
Solving Issue No. 2
The training process of our model is a Multi-objective Optimization (MOO) problem, where we have to minimize two objectives simultaneously: the conventional relation extraction loss and the knowledge distillation loss . State-of-the-art Multi-task Learning (MTL) frameworks [5, 6, 7, 8] can be employed to address this problem.
Nevertheless, it is essential to recognize that the current MTL frameworks were not originally developed for continual learning, and there are fundamental differences between the two paradigms. Specifically, at the beginning of training a new task, the objectives associated with maintaining performance on previously learned tasks are already in a better state than the objective related to learning new knowledge; however, current MTL approaches do not have mechanisms to leverage this information since they were not designed to handle such unique challenges encountered in continual learning settings.
To solve this issue, we propose a novel gradient-based MOO algorithm, Adaptive Unified Gradient Descent, which allows the learning process of the model to recognize the difference in magnitudes of different gradient signals, thereby prioritizing acquiring new knowledge.
Algorithm 1: Adaptive Unified Gradient Descent
Experimental Results
Main results
How our method compares to the current most successful CRE baselines:
Table 1: Performance of CREST (%) on all observed relations at each stage of learning, in comparison with SOTA CRE baselines.
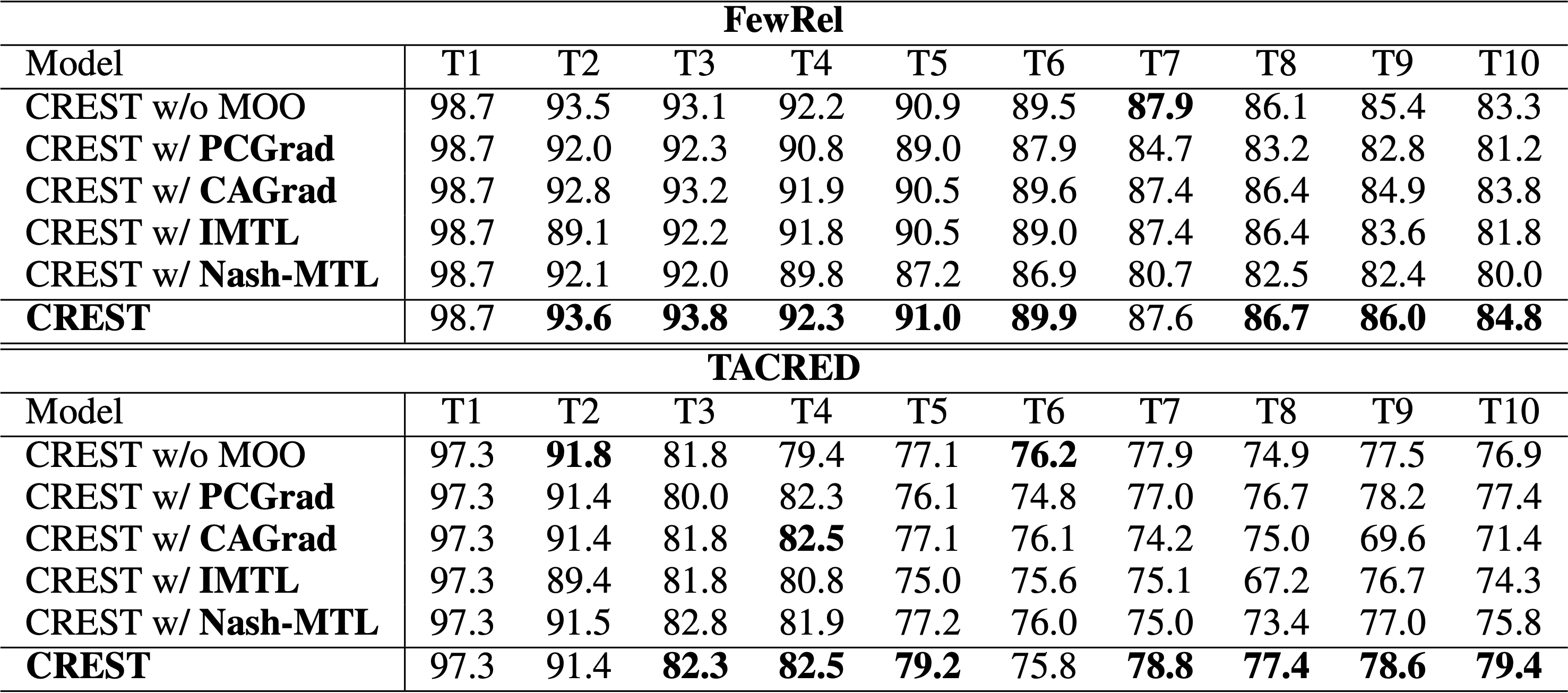
Effects of Choice of Gradient-Based MOO Method
To examine the effectiveness of our novel gradient-based MOO method designed for Continual Learning (CL), we have benchmarked our method in comparison against other SOTA MOO methods [5, 6, 7, 8]. The empirical results are presented in Table 2.
Table 2: Results of ablation studies on different MOO methods when applied to CREST.
Comparison to MOO Rehearsal-Free Continual Learning Methods
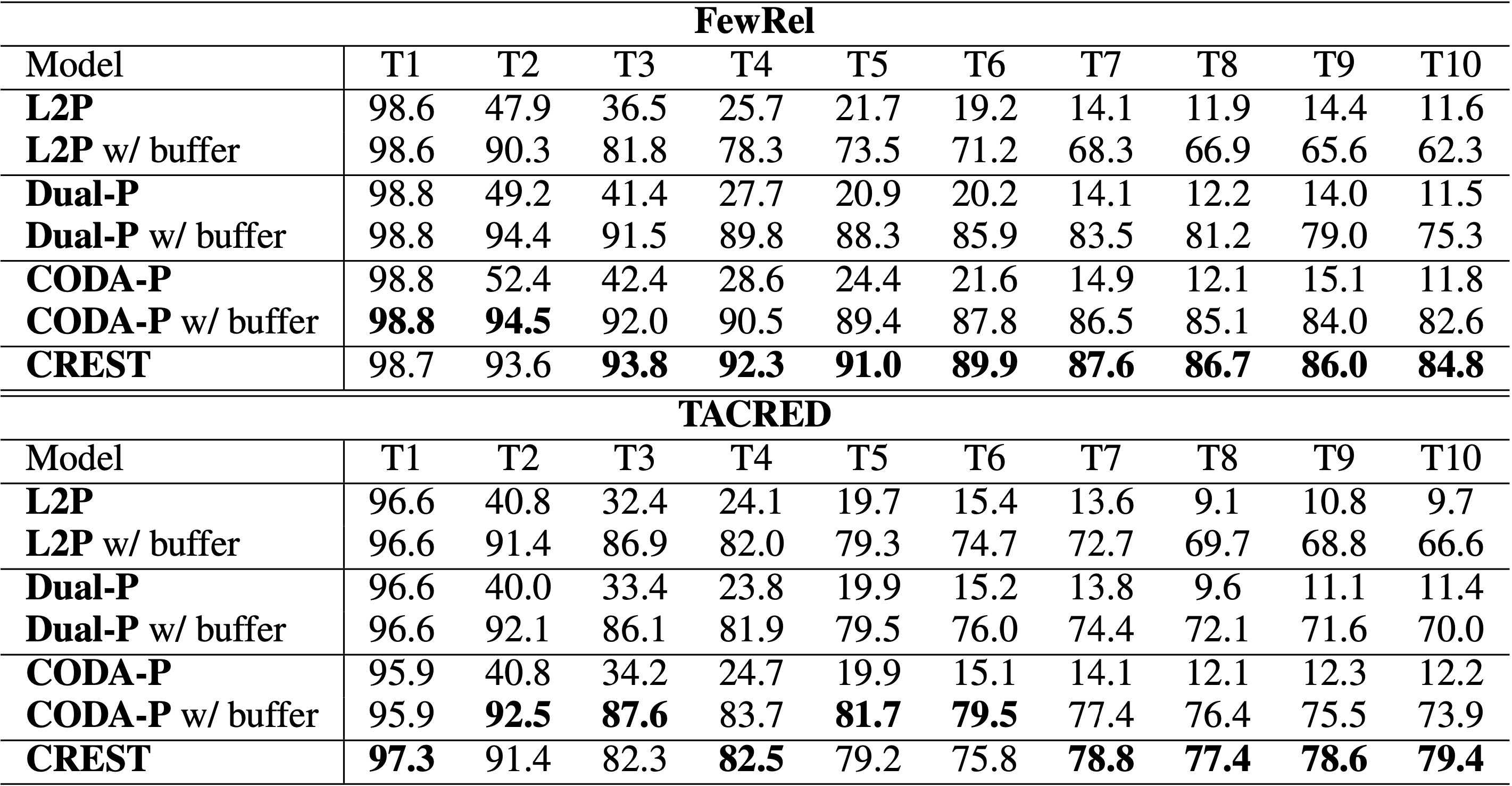
Recently, prompt-based methods for Continual Learning (CL) [9, 10, 11] have emerged as rehearsal-free and efficient-finetuning CL approaches, gaining attention due to their remarkable success in computer vision tasks, even surpassing SOTA memory-based methods. In similarity to CREST, these prompt-based methods neither require full finetuning of the backbone encoder nor rely on an explicit memory buffer. As such, it becomes essential to conduct a comparison between CREST and these prompt-based continual learning methods. So, how do we stack up against them?
Table 3: Comparison of our method’s performance (%) with state-of-the-art rehearsal-free Continual Learning baselines.
References
Hu, C.; Yang, D.; Jin, H.; Chen, Z.; and Xiao, Y. 2022. Improving Continual Relation Extraction through Prototypical Contrastive Learning. In Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju, Republic of Korea.
Zhao, K.; Xu, H.; Yang, J.; and Gao, K. 2022. Consistent Representation Learning for Continual Relation Extraction. In Findings of the Association for Computational Linguistics: ACL 2022. Dublin, Ireland.
Nguyen, H.; Nguyen, C.; Ngo, L.; Luu, A.; and Nguyen, T. 2023. A Spectral Viewpoint on Continual Relation Extraction. In Findings of the Association for Computational Linguistics: EMNLP 2023, 9621–9629.
Oord, A. v. d.; Li, Y.; and Vinyals, O. 2018. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.
Yu, T.; Kumar, S.; Gupta, A.; Levine, S.; Hausman, K.; and Finn, C. 2020. Gradient Surgery for Multi-Task Learning. In Advances in Neural Information Processing Systems. Virtual.
Liu, B.; Liu, X.; Jin, X.; Stone, P.; and Liu, Q. 2021a. Conflict-Averse Gradient Descent for Multi-task learning. In Advances in Neural Information Processing Systems. Virtual.
Liu, L.; Li, Y.; Kuang, Z.; Xue, J.-H.; Chen, Y.; Yang, W.; Liao, Q.; and Zhang, W. 2021b. Towards Impartial Multi-task Learning. In International Conference on Learning Representations. Virtual.
Navon, A.; Shamsian, A.; Achituve, I.; Maron, H.; Kawaguchi, K.; Chechik, G.; and Fetaya, E. 2022. Multi-Task Learning as a Bargaining Game. arXiv preprint arXiv:2202.01017.
Wang, Z.; Zhang, Z.; Lee, C.-Y.; Zhang, H.; Sun, R.; Ren, X.; Su, G.; Perot, V.; Dy, J.; and Pfister, T. 2022c. Learning to prompt for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, LA, USA.
Wang, Z.; Zhang, Z.; Ebrahimi, S.; Sun, R.; Zhang, H.; Lee, C.-Y.; Ren, X.; Su, G.; Perot, V.; Dy, J.; et al. 2022b. DualPrompt: Complementary prompting for rehearsal-free continual learning. In European Conference on Computer Vision. Tel Aviv, Israel.
Smith, J. S.; Karlinsky, L.; Gutta, V.; Cascante-Bonilla, P.; Kim, D.; Arbelle, A.; Panda, R.; Feris, R.; and Kira, Z. 2023. CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, BC, Canada.
 of all the data. This can be much more practical and feasible than fitting the model to the original embedding matrices of the text instances.
of all the data. This can be much more practical and feasible than fitting the model to the original embedding matrices of the text instances.  , for each relation type
, for each relation type  , we use a Gaussian Mixture Model (GMM) to learn the underlying data distribution of the relation representations
, we use a Gaussian Mixture Model (GMM) to learn the underlying data distribution of the relation representations  ), for each relation type
), for each relation type  synthetic relation representations:
synthetic relation representations:![\[\tilde{\bm{z}}_{n} \sim \sum\limits_{i=1}^K \pi^r_i \mathcal{N}( \mu^r_i, \Sigma^r_i), n = 1, 2, ...\tilde{n},\]](https://research.vinai.io/wp-content/ql-cache/quicklatex.com-027cfc2524b0872c1500467cc3857082_l3.svg "Rendered by QuickLaTeX.com")
 is the number of GMM components;
is the number of GMM components;  ,
,  and
and  are the mixing coefficient, mean and diagonal covariance of
are the mixing coefficient, mean and diagonal covariance of  Gaussian distribution, respectively.
Gaussian distribution, respectively. will facilitate the model in reinforcing its previous knowledge via knowledge distillation. The distillation loss facilitates continual learning by transferring knowledge from previous tasks to the current task, enabling the model to retain previously learned information and avoid catastrophic forgetting.
will facilitate the model in reinforcing its previous knowledge via knowledge distillation. The distillation loss facilitates continual learning by transferring knowledge from previous tasks to the current task, enabling the model to retain previously learned information and avoid catastrophic forgetting. and the knowledge distillation loss
and the knowledge distillation loss  . State-of-the-art Multi-task Learning (MTL) frameworks [5, 6, 7, 8] can be employed to address this problem.
. State-of-the-art Multi-task Learning (MTL) frameworks [5, 6, 7, 8] can be employed to address this problem.