BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
October 27, 2022
1. Motivations
The masked language model BERT and its variants, pre-trained on large-scale corpora, help improve the state-of-the-art performances of various natural language understanding tasks. However, due to a bidirectionality nature, it might be difficult to directly apply those pre-trained language models to natural language generation tasks. Therefore, pre-trained sequence-to-sequence (seq2seq) models, e.g. BART and T5, are proposed to handle this issue. The success of these pre-trained seq2seq models has largely been limited to the English language. For other languages, one could employ existing pre-trained multilingual seq2seq models, e.g. mBART and mT5, or retrain language-specific models using the proposed seq2seq architectures. It is worth noting that retraining a language-specific model might be preferable as dedicated language-specific models still outperform multilingual ones.
Regarding Vietnamese, to the best of our knowledge, there is not an existing monolingual seq2seq model pre-trained for Vietnamese. In addition, another concern is that all publicly available pre-trained multilingual seq2seq models are not aware of the linguistic characteristic difference between Vietnamese syllables and word tokens.
2. How we handle the two concerns above
To handle the concerns above, we train first large-scale monolingual seq2seq pre-trained models for Vietnamese, which we name BARTpho-syllable (a syllable-level model) and BARTpho-word (a word-level model). BARTpho models use the “large” version of the standard architecture Transformer but employ the GeLU activation function rather than ReLU. We also add a layer-normalization layer on top of both the encoder and decoder. We use the same pre-training scheme of the seq2seq denoising autoencoder BART, which has two stages:
Corrupting the input text with an arbitrary noising function (here, we employ two types of noise in the noising function, including text infilling and sentence permutation).
Learning to reconstruct the original text, i.e. optimizing the cross-entropy between its decoder’s output and the original text.
For BARTpho-word, we employ the PhoBERT pre-training corpus that contains 20GB of uncompressed texts (about 145M automatically word-segmented sentences). In addition, we also reuse the PhoBERT tokenizer to segment those word-segmented sentences with subword units. Pre-training data for BARTpho-syllable is a detokenized variant of the PhoBERT pre-training corpus (i.e. about 4B syllable tokens). We employ the pre-trained SentencePiece model used in mBART to segment sentences with sub-syllable units and select a vocabulary of the top 40K most frequent types. For each BARTpho model, we run for 15 training epochs in about 6 days, using a batch size of 512 sequence blocks across 8 A100 GPUs (40GB each).
3. How we evaluate BARTpho
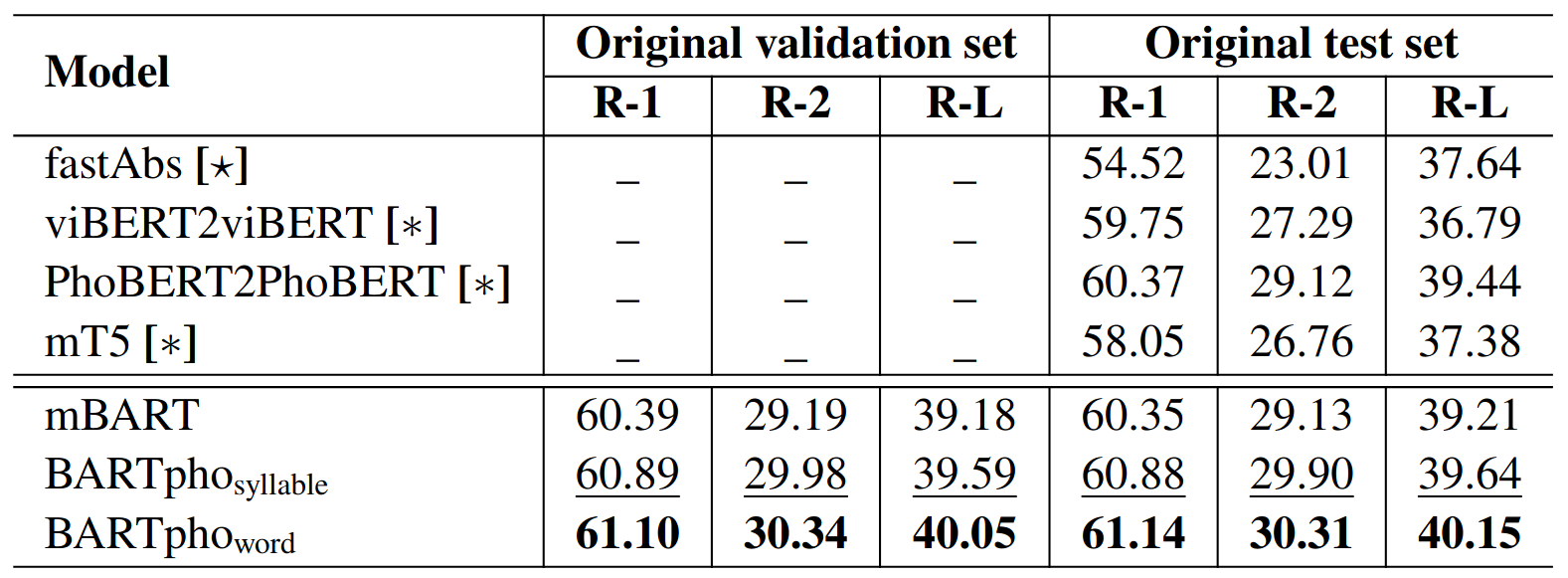
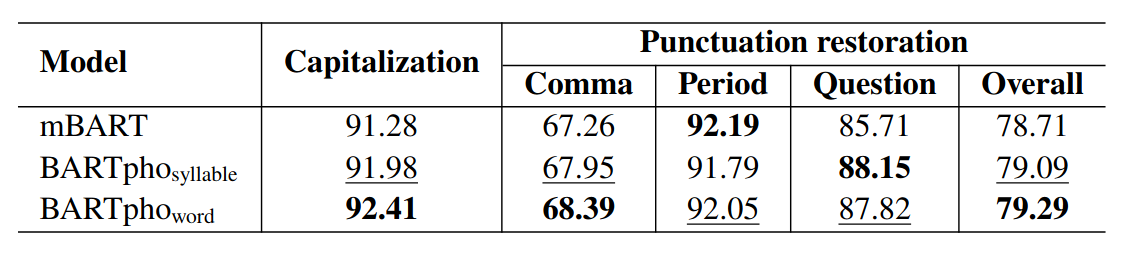
We evaluate and compare the performance of BARTpho models with the strong baseline mBART on three downstream tasks: Vietnamese text summarization, Vietnamese capitalization and punctuation restoration. Tables 1 and 2 show that our BARTpho outperforms mBART, where BARTpho-word obtains the highest overall scores.
Table 1: Vietnamese text summarization results.
Table 2: Vietnamese capitalization and punctuation restoration results.
The results from tables 1 and 2 demonstrate the effectiveness of large-scale BART-based monolingual seq2seq models for Vietnamese. Note that mBART uses 137 / 20 ~ 7 times bigger Vietnamese pre-training data than BARTpho. However, BARTpho surpasses mBART, reconfirming that the dedicated language-specific model still performs better than the multilingual one. In addition, BARTpho-word outperforms BARTpho-syllable, thus demonstrating the positive influence of word segmentation for seq2seq pre-training and fine-tuning in Vietnamese.
4. Why it matters
We have introduced BARTpho with two versions BARTpho-syllable and BARTpho-word, which are the first public large-scale monolingual seq2seq models pre-trained for Vietnamese. We empirically conduct experiments to demonstrate that BARTpho models outperform their competitor mBART in the tasks of Vietnamese text summarization and Vietnamese capitalization and punctuation restoration.
We publicly release our BARTpho to work with popular open-source libraries fairseq and transformers, hoping that BARTpho can serve as a strong baseline for future research and applications of generative Vietnamese NLP tasks.