SyntaGen @ CVPR’24
The field of computer vision has undergone a significant transformation in recent years with the advancement of generative models, particularly text-to-image models such as Imagen, Stable Diffusion, and DALLE-3. These models have enabled the creation of synthetic visual datasets that are highly realistic and diverse, complete with annotations and rich variations. These datasets have proven to be extremely valuable in training and evaluating various computer vision algorithms, including object detection and segmentation, representation learning, and scene understanding.
The SyntaGen workshop will act as a crucible for an inclusive exchange of ideas, practical insights, and collaborative explorations. By convening experts and enthusiasts from various corners of the field, it strives to propel the development of generative models and synthetic visual datasets to new heights. Through informative talks, challenges, poster sessions, paper presentations, and vibrant panel discussions, this workshop endeavors to lay the foundation for innovative breakthroughs that bridge the realms of generative models and computer vision applications.
Speakers

Calls for Papers
We invite papers to propel the development of generative models and/or the use of their synthetic visual datasets for training and evaluating computer vision models. Accepted papers will be presented in the poster session in our workshop. We welcome submissions along two tracks:
- Full papers: Up to 8 pages, excluding references, with option for inclusion in the proceedings.
- Short papers: Up to 4 pages, excluding references, not for the proceedings.
Only full papers will be considered for the Best Paper award. Additionally, we offer a Best Paper and a Best Paper Runner-up award with oral presentations. All accepted papers without inclusion in the proceedings are non-archival.
For details of topics and guidelines, kindly visit: HERE.
Important Dates
- Submission: March 22nd, 11:59 PM Pacific Time
- Acceptance Notification: April 7th, 11:59 PM Pacific Time
- Camera Ready: April 14th, 11:59 PM Pacific Time
- Workshop Date: June 17th, 2024 (Morning)
SyntaGen Competition
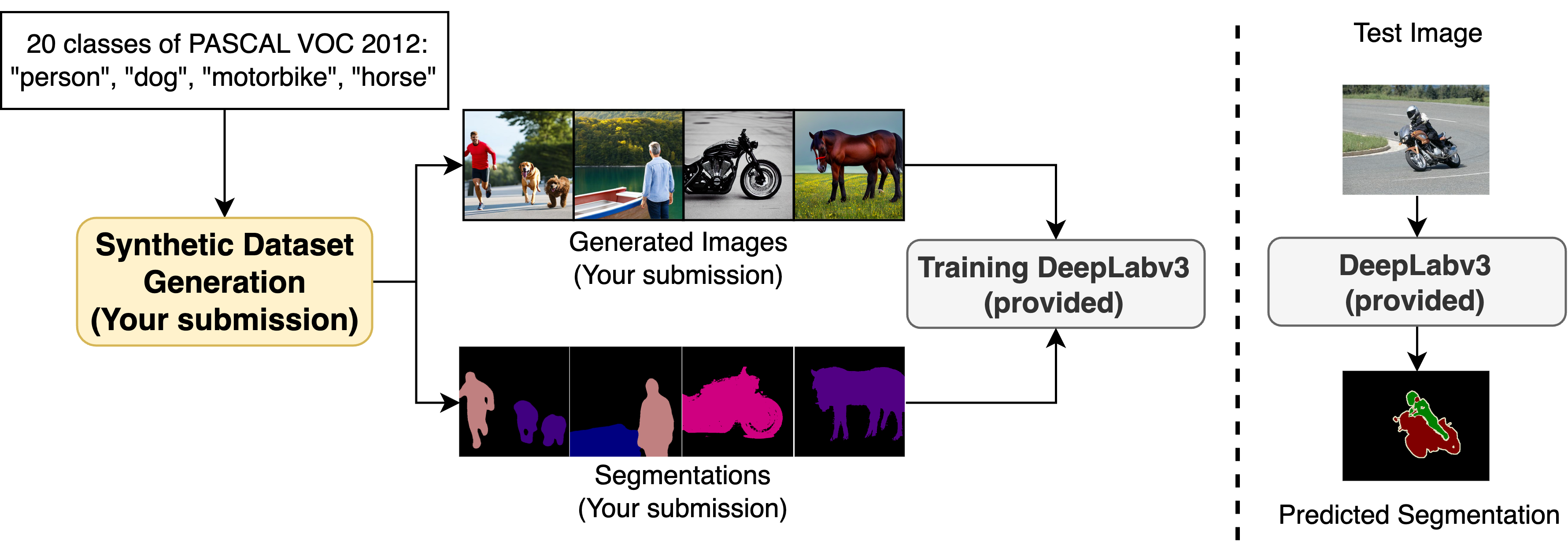
The primary objective of this competition is to drive innovation in the creation of high-quality synthetic datasets, leveraging only the pretrained Stable Diffusion and the 20 class names from PASCAL VOC 2012 for semantic segmentation. The evaluation of synthetic dataset quality involves training a DeepLabv3 model on the synthetic dataset and subsequently assessing its performance on a private test set on the task of semantic segmentation (a sample validation set is the validation set of PASCAL VOC 2012). Submissions are ranked based on the mIoU metric. This competition framework mirrors the practical application of synthetic datasets, particularly in scenarios where they replace real datasets.
Prizes
We will award the top 2 teams with cash prizes (Rank 1: $1000, Rank 2: $500) and invite them to write a report and present their work at the workshop (10 minutes each).
Important Dates
- Submission start: Mar 1st, 2024
- Submission deadline 1 for random seed, DeepLabv3, and dataset: May 24th, 2024
- Submission deadline 2 for dataset generation code and mIoU score: May 27th, 2024
- Award announcement: Jun 7th, 2024
- Report and code upload for winners: Jun 14th, 2024
For details of competitions and guidelines, kindly visit: HERE.
Overall
Time
Mon, Jun 17 2024 - 09:00 am (GMT + 7)Language
EnglishYour Question
Ask speaker question at
https://discord.gg/AMxnPm3V