Bringing Intelligence to Every Drive
01
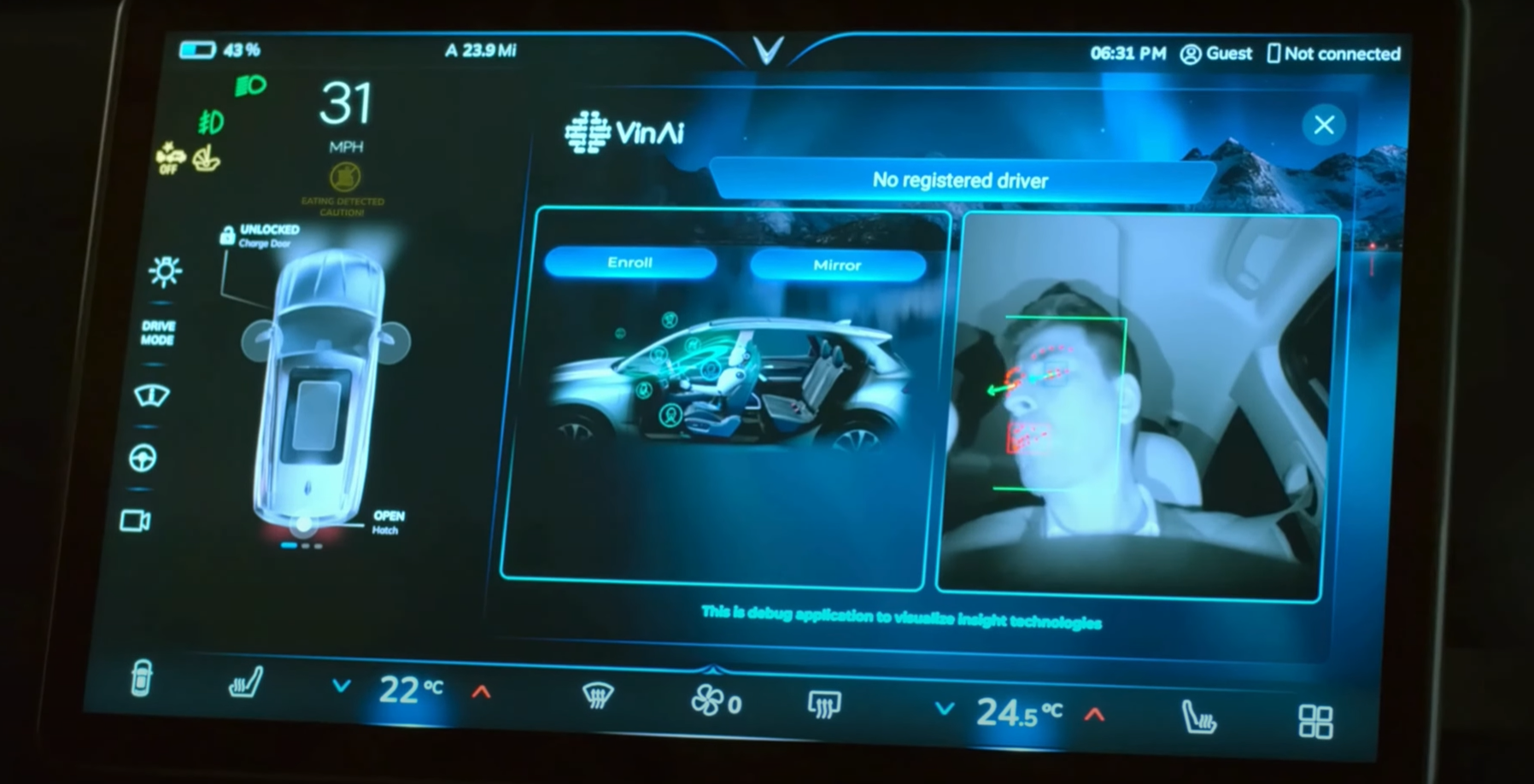
InteriorSenseDriver Monitoring System
Our Driver Monitoring System offers accurate, real-time in-cabin monitoring to enhance driver safety and help OEMs meet regulatory requirements. It detects signs of fatigue, distraction, and risky behaviors, making every journey safer and smarter.
Watch Demo
01
InteriorSenseDriver Monitoring System
Our Driver Monitoring System offers accurate, real-time in-cabin monitoring to enhance driver safety and help OEMs meet regulatory requirements. It detects signs of fatigue, distraction, and risky behaviors, making every journey safer and smarter.
Watch Demo
01
InteriorSenseDriver Monitoring System
Our Driver Monitoring System offers accurate, real-time in-cabin monitoring to enhance driver safety and help OEMs meet regulatory requirements. It detects signs of fatigue, distraction, and risky behaviors, making every journey safer and smarter.
Watch Demo02
InteriorSenseMirrorSense
MirrorSense is the world's first AI-driven automatic mirror adjustment technology that has been honored with the Innovation Award Honoree at CES 2024. This technology can be easily expanded to enhance safety applications while driving, such as augmented reality heads-up displays and auto-adjust seat settings.
Watch Demo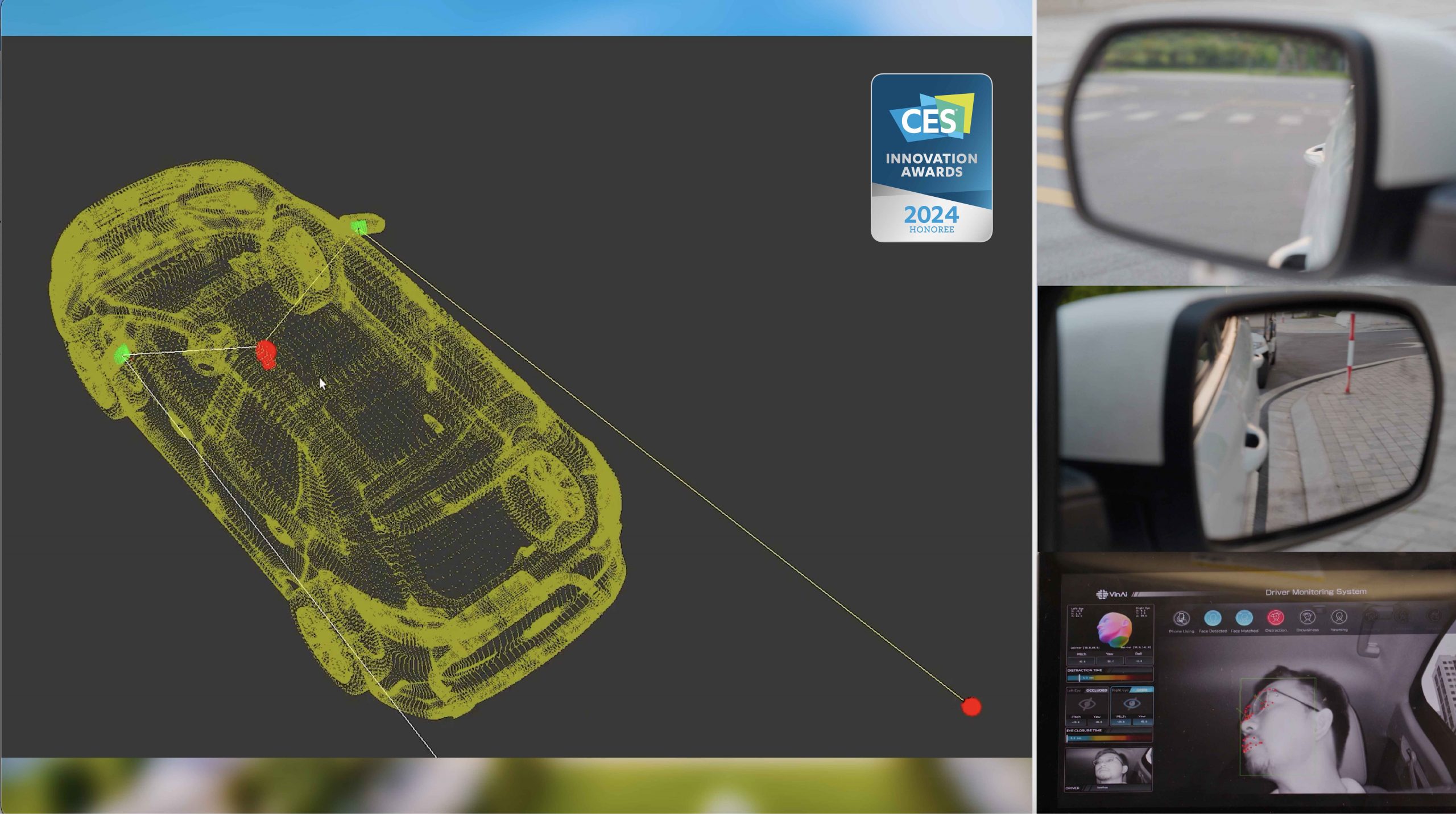
02
InteriorSenseDrunkSense
DrunkSense is the world’s first passive drunk impairment detection system that works without a breathalyzer. It has a 85% sensitivity.
Watch Demo
02
InteriorSenseMirrorSense
MirrorSense is the world's first AI-driven automatic mirror adjustment technology that has been honored with the Innovation Award Honoree at CES 2024. This technology can be easily expanded to enhance safety applications while driving, such as augmented reality heads-up displays and auto-adjust seat settings.
Watch Demo
02
InteriorSenseDrunkSense
DrunkSense is the world’s first passive drunk impairment detection system that works without a breathalyzer. It has a 85% sensitivity.
Watch Demo
03
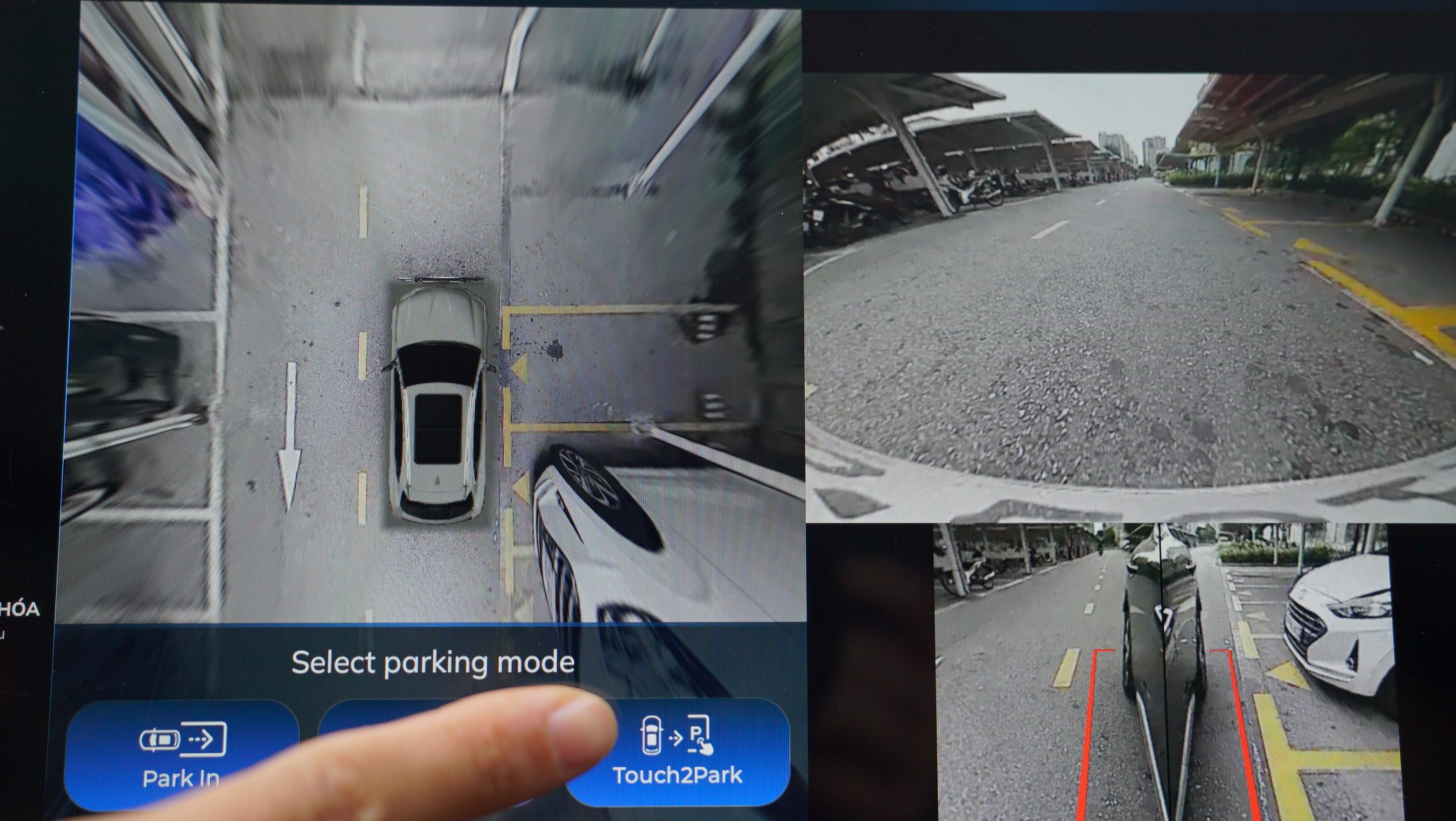
SurroundSenseSmart Parking - Touch2Park
Touch2Park is the winner of the 2024 AutoTech Breakthrough Award. This Level 2 smart parking solution enables effortless parking by a simple touch. It can adapt to diverse parking situations.
Watch Demo
03
SurroundSenseSmart Parking - Touch2Park
Touch2Park is the winner of the 2024 AutoTech Breakthrough Award. This Level 2 smart parking solution enables effortless parking by a simple touch. It can adapt to diverse parking situations.
Watch Demo
03
SurroundSenseSmart Parking - Touch2Park
Touch2Park is the winner of the 2024 AutoTech Breakthrough Award. This Level 2 smart parking solution enables effortless parking by a simple touch. It can adapt to diverse parking situations.
Watch Demo04
SurroundSenseJellyView
JellyView allows drivers to gain a clear view beneath their vehicle. The view is constructed using images from sensors and cameras, enabling JellyView to be seamlessly integrated into existing vehicles without additional hardware.
Watch Demo
04
SurroundSenseAdvanced Surround View Monitoring System
Our multi-camera system provides drivers with a complete real-time view around the vehicle and the ability to see through the entire car body.
Watch Demo
04
SurroundSenseJellyView
JellyView allows drivers to gain a clear view beneath their vehicle. The view is constructed using images from sensors and cameras, enabling JellyView to be seamlessly integrated into existing vehicles without additional hardware.
Watch Demo
04
SurroundSenseAdvanced Surround View Monitoring System
Our multi-camera system provides drivers with a complete real-time view around the vehicle and the ability to see through the entire car body.
Watch Demo
AI Talent
At VinAI, we believe that great things happen when passionate individuals come together. We're constantly on the lookout for talented, motivated, and creative individuals who can contribute to our success. If you're looking for a dynamic and rewarding career in the technology industry, you've come to the right place.
Join Our Team
Recognized by Global Partners and Media