ISBNet: a 3D Point Cloud Instance Segmentation Network with Instance-aware Sampling and Box-aware Dynamic Convolution
July 21, 2023
1. Introduction
Existing 3D instance segmentation methods are predominated by the bottom-up design – manually fine-tuned algorithm to group points into clusters followed by a refinement network. However, by relying on the quality of the clusters, these methods generate susceptible results when (1) nearby objects with the same semantic class are packed together, or (2) large objects with loosely connected regions. To address these limitations, we introduce ISBNet, a novel cluster-free method that represents instances as kernels and decodes instance masks via dynamic convolution. To efficiently generate high-recall and discriminative kernels, we propose a simple strategy named Instance-aware Farthest Point Sampling to sample candidates and leverage the local aggregation layer inspired by PointNet++ to encode candidate features. Moreover, we show that predicting and leveraging the 3D axis-aligned bounding boxes in the dynamic convolution further boosts performance. Our method set new state-of-the-art results on ScanNetV2 (55.9), S3DIS (60.8), and STPLS3D (49.2) in terms of AP and retains fast inference time (237ms per scene on ScanNetV2). The source code and trained models are available at https://github.com/VinAIResearch/ISBNet.
2. Method
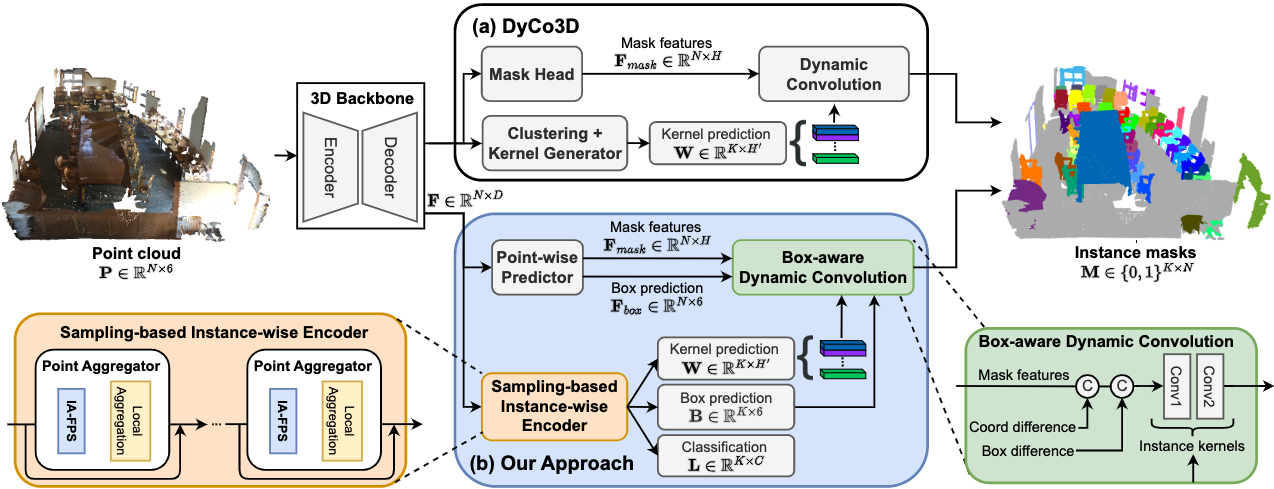
Figure 1. Overall architectures of DyCo3D [1] (block (a)) and our approach (block (b)) for 3D instance segmentation.
2.1. Problem Statement
Given a 3D point cloud where is the number of points, and each point is represented by a 3D position and RGB color vector.
We aim to segment the point cloud into instances that are represented by a set of binary masks and a set of semantic labels , where is the number of semantic categories.
Our method consists of four main components: a 3D backbone, a point-wise predictor, a sampling-based instance-wise encoder, and a box-aware dynamic convolution.
The 3D backbone takes a 3D point cloud as input to extract per-point features. The point-wise predictor takes per-point features from the backbone and transforms them into point-wise semantic predictions, axis-aligned bounding box predictions, and mask features for box-aware dynamic convolution. The sampling-based instance-wise encoder processes point-wise features to generate instance kernels, instance class labels, and bounding box parameters. Finally, the box-aware dynamic convolution gets the instance kernels and the mask features with the complementary box prediction to generate the final binary mask for each instance.
2.2. Sampling-based Instance-wise Encoder
We propose our instance encoder comprising a sequence of Point Aggregator (PA) blocks whose components are Instance-Aware FPS (IA-FPS) to sample candidate points covering as many foreground objects as possible and a local aggregation layer to capture the local context so as to enrich the candidate features individually. We visualize the PA in the orange block in Fig. 1.
Instance-aware FPS. Our sampling strategy is to sample foreground points to maximally cover all instances regardless of their sizes. To achieve this goal, we opt for an iterative sampling technique as follows. Specifically, candidates are sampled from a set of points that are neither background nor chosen by previous sampled candidates.
We use the point-wise semantic prediction to estimate the probability for each point to be background . We also use the instance masks generated by previous -th candidate . The FPS is leveraged to sample points from the set of points .
Local aggregation layer. For each candidate , the local aggregation layer encodes and transforms the local context into its instance-wise features.
where is the number of already chosen candidates and , is the hyper-parameter threshold.
2.3. Box-aware Dynamic Convolution
3D bounding box delineates the shape and size of an object, which provides an important geometric cue for the prediction of object masks in instance segmentation.
Our method uses bounding box predictions as an auxiliary task that regularizes instance segmentation training. Particularly, for each point, we propose to regress the axis-aligned bounding box deduced from the object mask. The predicted boxes are then used to condition the mask feature to generate kernels for the box-aware dynamic convolution (green block) in Fig. 1.
3. Experiments
3.1 Datasets
We evaluate our method on three datasets: ScanNetV2 [5], S3DIS [6], and STPLS3D [7]. The ScanNetV2 dataset consists of 1201, 312, and 100 scans with 18 object classes for training, validation, and testing, respectively. We report the evaluation results on the official test set of ScanNetV2. The S3DIS dataset contains 271 scenes from 6 areas with 13 categories. We report evaluations for both Area 5 and 6-fold cross-validation.
The STPLS3D dataset is an aerial photogrammetry point cloud dataset from real-world and synthetic environments. It includes 25 urban scenes of a total of 6km and 14 instance categories. Following [7], we use scenes 5, 10, 15, 20, and 25 for validation and the rest for training.
3.2. Quantitative results
Table 1. 3D instance segmentation results on ScanNetV2 hidden test set.
We report the instance segmentation results on the hidden test set in Tab. 1. ISBNet achieves 55.9/76.6 in AP/AP, set a new state-of-the-art performance on ScanNetV2 benchmark.
In Tab. 2, on both Area 5 and cross-validation evaluations of S3DIS, our proposed method overtakes the strongest method by large margins in almost metrics. On the 6-fold cross-validation evaluation, we achieve 74.9/76.8/77.1 in mCov/mWCov/mRec, with an improvement of compared with the second-strongest method.
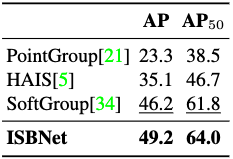
Tab. 3 shows the results of the validation set of the STPLS3D dataset. Our method achieves the highest performance in all metrics and surpasses the second-best by in AP/AP.
Table 2. 3D instance segmentation results on S3DIS dataset. Methods marked with † are evaluated on Area 5, and methods marked with ‡ are evaluated on 6-fold cross-validation.
Table 3. 3D instance segmentation results on STPLS3D validation set.
Table 4. Impact of each component of ISBNet on ScanNetV2 validation set. IA-FPS: Instance-aware Farthest Point Sampling, LAL: Local Aggregation Layer, BA-DyCo: Box-aware Dynamic Convolution. ∗: our improved version of DyCo3D
The impact of each component on the overall performance is shown in Tab. 4. The baseline in row 2 is a model with standard Farthest Point Sampling (FPS), standard Dynamic Convolution and without Local Aggregation Layer (LAL) . It can be seen that replacing the clustering and the tiny Unet in DyCo3D decreases the performance from 49.4 to 47.9 in AP. When the standard FPS in the baseline is replaced by the Instance-aware Farthest Point Sampling (IA-FPS), the performance improves to 49.7 in row 3. When adding LAL to the baseline model, the AP score increases to 50.1 in row 4 and outperforms the AP of DyCo3D by 0.7. Finally, the full approach in row 7, \Approach~achieves the best performance 54.5/73.1 in AP/AP.
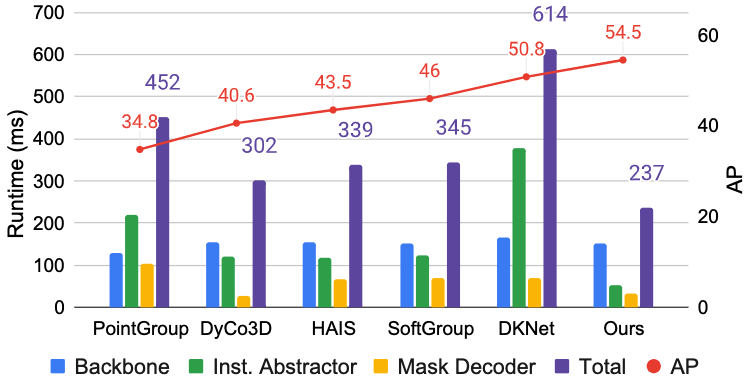
Figure 2. Components and total runtimes (in ms) and results in AP of five previous methods and ISBNet on ScanNetV2 validation set.
Fig. 3 reports the component and total runtimes of ISBNet and 5 recent state-of-the-art methods of 3DIS on the same Titan X GPU. All the methods can be roughly separated into three main stages: backbone, instance abstractor, and mask decoder. Our method is the fastest method, with only 237ms in total runtime and 152/53/32ms in backbone/instance abstractor/mask decoder stages. Compared with the instance abstractors in PointGroup [3], DyCo3D [1], and SoftGroup [4] which are based on clustering, our instance abstractor based on our Point Aggregator significantly reduce the runtime. Our mask decoder, which is implemented by dynamic convolution, is the second fastest among these methods. This proves the efficiency of our proposed method.
3.3. Qualitative results
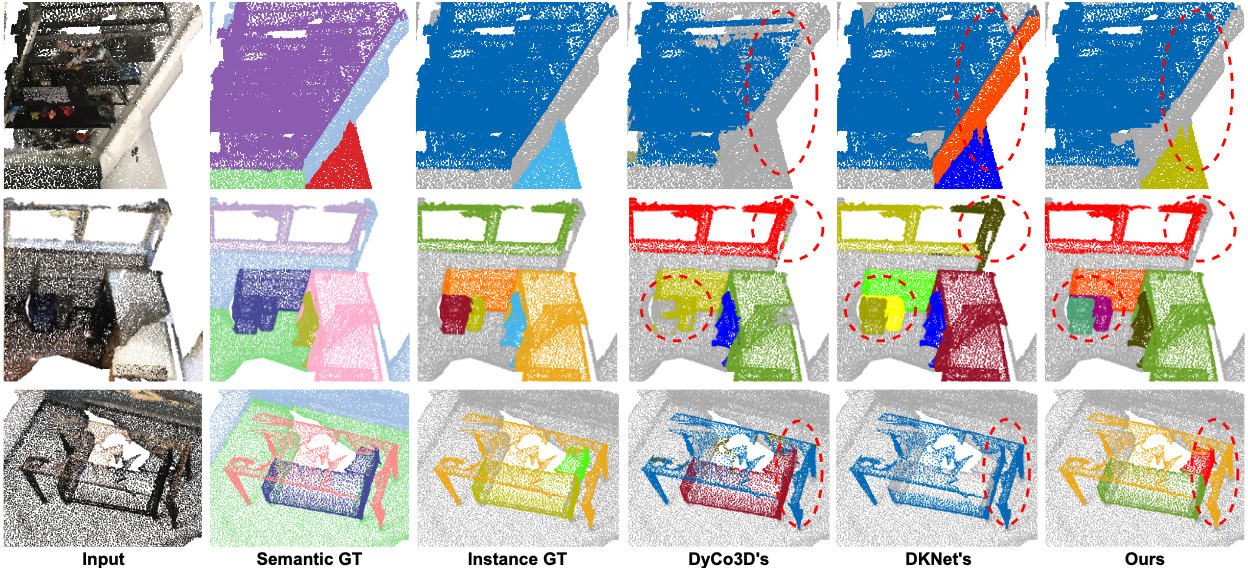
Figure 3. Representative examples on ScanNetV2 validation set. Each row shows an example with the input, Semantic ground truth, and Instance ground truth in the first three columns. Our method (the last column) produces more precise instance masks, especially in regions where multiple instances with the same semantic label lie together.
We visualize the qualitative results of our method, DyCo3D [1], and DKNet [2] on ScanNetV2 validation set in Fig. 4. As can be seen, our method successfully distinguishes nearby instances with the same semantic class. Due to the limitation of clustering, DyCo3D [1] mis-segments parts of the bookshelf (row 1) and merges nearby sofas (rows 2, 3). DKNet [2] over-segments the window in row 2, and also wrongly merges nearby sofas and table (row 3).
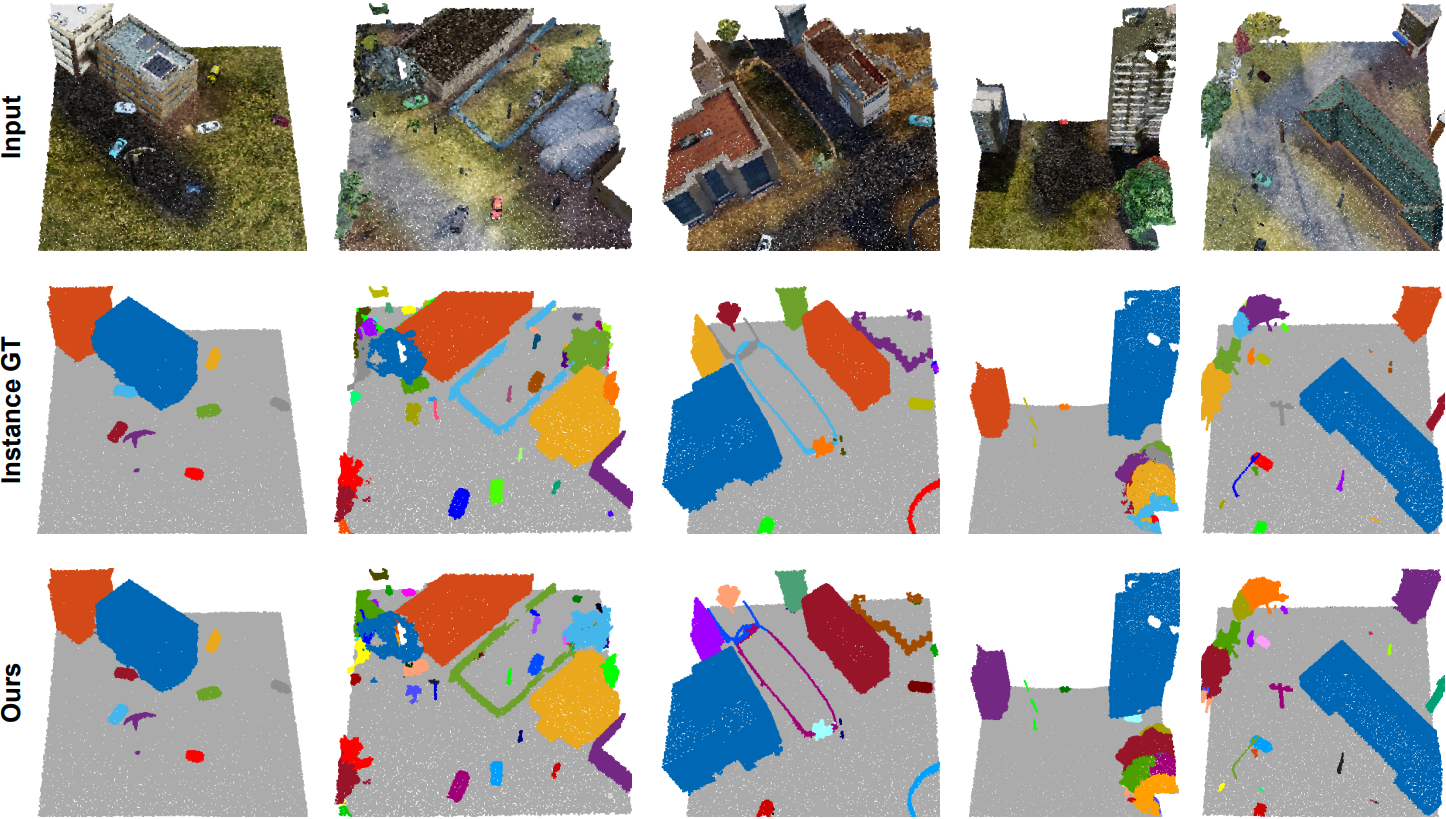
More qualitative results of our approach on the ScanNetV2, S3DIS, and STPLS3D datasets are visualized in Fig. 5, Fig. 6, and Fig. 7, respectively
Figure 4. Qualitative results on ScanNetV2 dataset. Each column shows one example.
Figure 5. Qualitative results on S3DIS dataset. Each column shows one example.
Figure 6. Qualitative results on S3DIS dataset. Each column shows one example.
4. Conclusion
In this work, we have introduced the ISBNet, a concise dynamic convolution-based approach to address the task of 3D point cloud instance segmentation. Considering the performance of instance segmentation models relying on the recall of candidate queries, we propose our Instance-aware Farthest Point Sampling and Point Aggregator to efficiently sample candidates in the 3D point cloud. Additionally, leveraging the 3D bounding box as auxiliary supervision and a geometric cue for dynamic convolution further enhances the accuracy of our model. Extensive experiments on ScanNetV2, S3DIS, and STPLS3D datasets show that our approach achieves robust and significant performance gain on all datasets, surpassing state-of-the-art approaches in 3D instance segmentation by large margins, i.e., +2.7, +2.4, +3.0 in AP on ScanNetV2, S3DIS and STPLS3D.
5. References
[1] T. He, C. Shen, and A. van den Hengel. Dyco3d: Robust instance segmentation of 3d point clouds through dynamic convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2021.
[2] Y. Wu, M. Shi, S. Du, H. Lu, Z. Cao, and W. Zhong. 3d instances as 1d kernels. In Proceedings of the European Conference on Computer Vision, 2022.
[3] L. Jiang, H. Zhao, S. Shi, S. Liu, C.-W. Fu, and J. Jia. Pointgroup: Dual-set point grouping for 3d instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020.
[4] T. Vu, K. Kim, T. M. Luu, X. T. Nguyen, and C. D. Yoo. Softgroup for 3d instance segmentation on 3d point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022.
[5] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[6] I. Armeni, S. Sax, A. R. Zamir, and S. Savarese. Joint 2d-3d semantic data for indoor scene understanding. arXiv preprint arXiv:1702.01105, 2017.
[7] M. Chen, Q. Hu, Z. Yu, H. THOMAS, A. Feng, Y. Hou, K. McCullough, F. Ren, and L. Soibelman. Stpls3d: A large-scale synthetic and real aerial photogrammetry 3d point cloud dataset. In Proceedings of the British Machine Vision Conference, 2022.
 where
where  is the number of points, and each point is represented by a 3D position and RGB color vector.
is the number of points, and each point is represented by a 3D position and RGB color vector. instances that are represented by a set of binary masks
instances that are represented by a set of binary masks  and a set of semantic labels
and a set of semantic labels  , where
, where  is the number of semantic categories.
is the number of semantic categories.![m^{(i)}_{(0)} \in [0, 1]](https://research.vinai.io/wp-content/ql-cache/quicklatex.com-88f29c46f8e4016ff1992a4ea32d6317_l3.svg "Rendered by QuickLaTeX.com") . We also use the instance masks generated by previous
. We also use the instance masks generated by previous  -th candidate
-th candidate ![m^{(i)}_{(k)} \in [0, 1]](https://research.vinai.io/wp-content/ql-cache/quicklatex.com-ff7d6024a663aff82d37e3c3b0ee1232_l3.svg "Rendered by QuickLaTeX.com") . The FPS is leveraged to sample points from the set of points
. The FPS is leveraged to sample points from the set of points  .
. is the number of already chosen candidates and
is the number of already chosen candidates and  , is the hyper-parameter threshold.
, is the hyper-parameter threshold.  and 14 instance categories. Following [7], we use scenes 5, 10, 15, 20, and 25 for validation and the rest for training.
and 14 instance categories. Following [7], we use scenes 5, 10, 15, 20, and 25 for validation and the rest for training.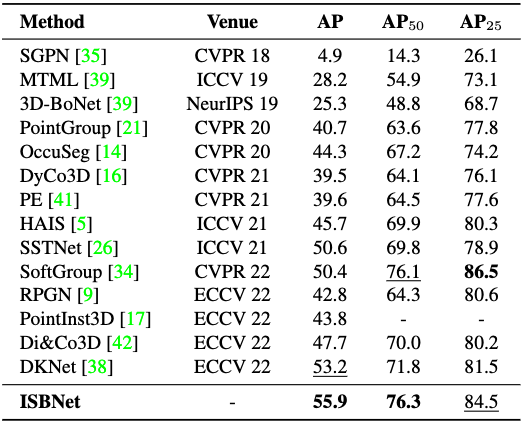
 , set a new state-of-the-art performance on ScanNetV2 benchmark.
, set a new state-of-the-art performance on ScanNetV2 benchmark.  compared with the second-strongest method.
compared with the second-strongest method. in AP/AP
in AP/AP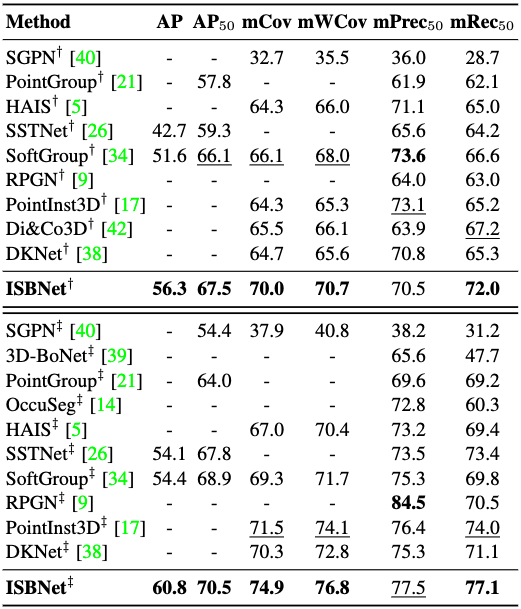
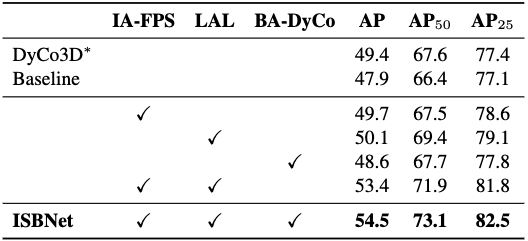
 decreases the performance from 49.4 to 47.9 in AP. When the standard FPS in the baseline is replaced by the Instance-aware Farthest Point Sampling (IA-FPS), the performance improves to 49.7 in row 3. When adding LAL to the baseline model, the AP score increases to 50.1 in row 4 and outperforms the AP of DyCo3D
decreases the performance from 49.4 to 47.9 in AP. When the standard FPS in the baseline is replaced by the Instance-aware Farthest Point Sampling (IA-FPS), the performance improves to 49.7 in row 3. When adding LAL to the baseline model, the AP score increases to 50.1 in row 4 and outperforms the AP of DyCo3D