Anti-DreamBooth: Protecting users from personalized text-to-image synthesis
March 22, 2024
1. Introduction
Text-to-image diffusion models are nothing but a revolution, allowing anyone, even without design skills, to create realistic images from simple text inputs. With powerful personalization tools like DreamBooth, they can generate images of a specific person just by learning from his/her few reference images. However, when misused, such a powerful and convenient tool can produce fake news or disturbing content targeting any individual victim, posing a severe negative social impact. In this paper, we explore a defense system called Anti-DreamBooth against such malicious use of DreamBooth. The system aims to add subtle noise perturbation to each user’s image before publishing in order to disrupt the generation quality of any DreamBooth model trained on these perturbed images. We investigate a wide range of algorithms for perturbation optimization and extensively evaluate them on two facial datasets over various text-to-image model versions. Despite the complicated formulation of DreamBooth and Diffusion-based text-to-image models, our methods effectively defend users from the malicious use of those models. Their effectiveness withstands even adverse conditions, such as model or prompt/term mismatching between training and testing. Our code is available at https://github.com/VinAIResearch/Anti-DreamBooth
2. Defense Scenario
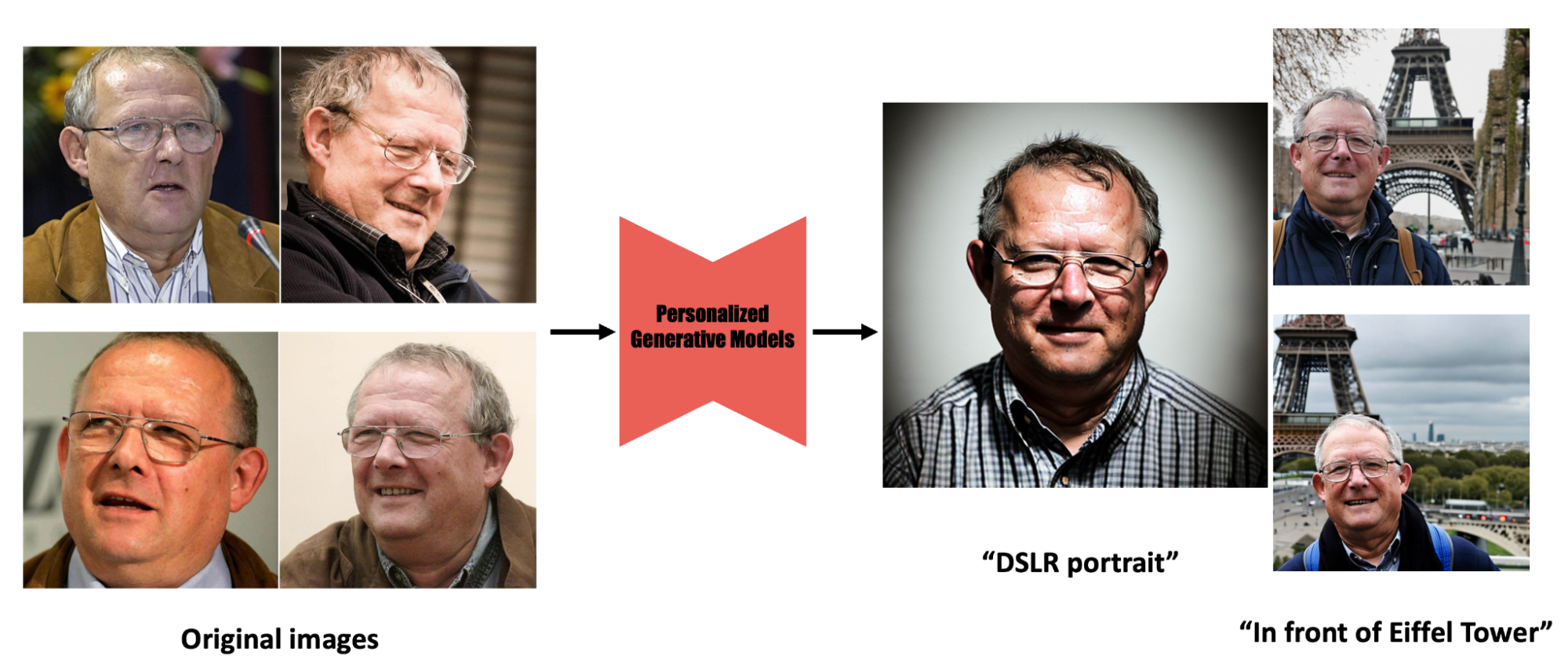
Figure 1: Personalized text-to-image models like DreamBooth [1] can be a powerful creative tool. By fine-tuning on user’s images, they can generate realistic images of that subject in different scenarios just by adjusting the text prompt.
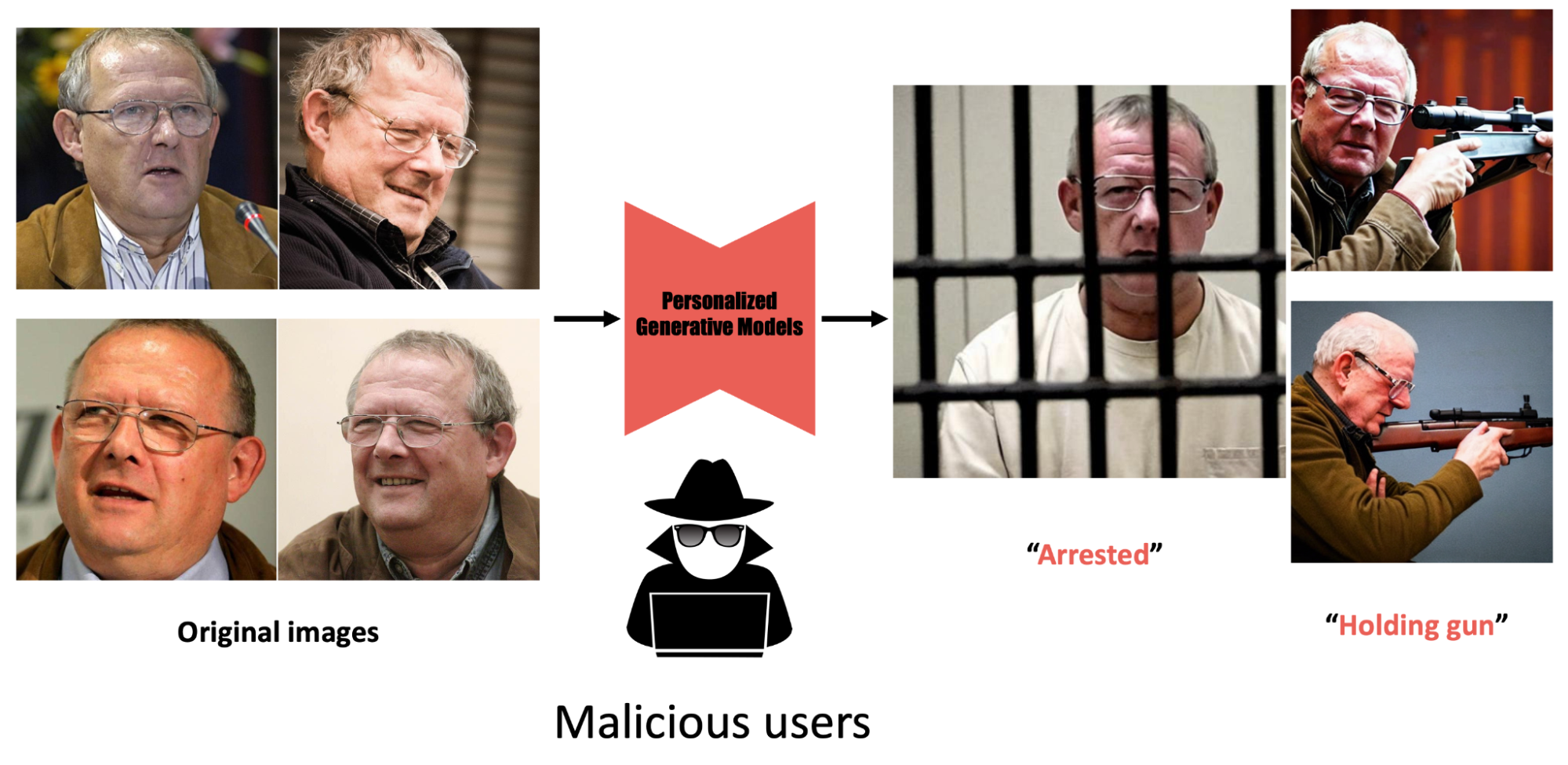
Figure 2: But if it falls into malicious hands, it could be used to create fake content targeting users without their consent, and currently there is no way to protect users from this threat.
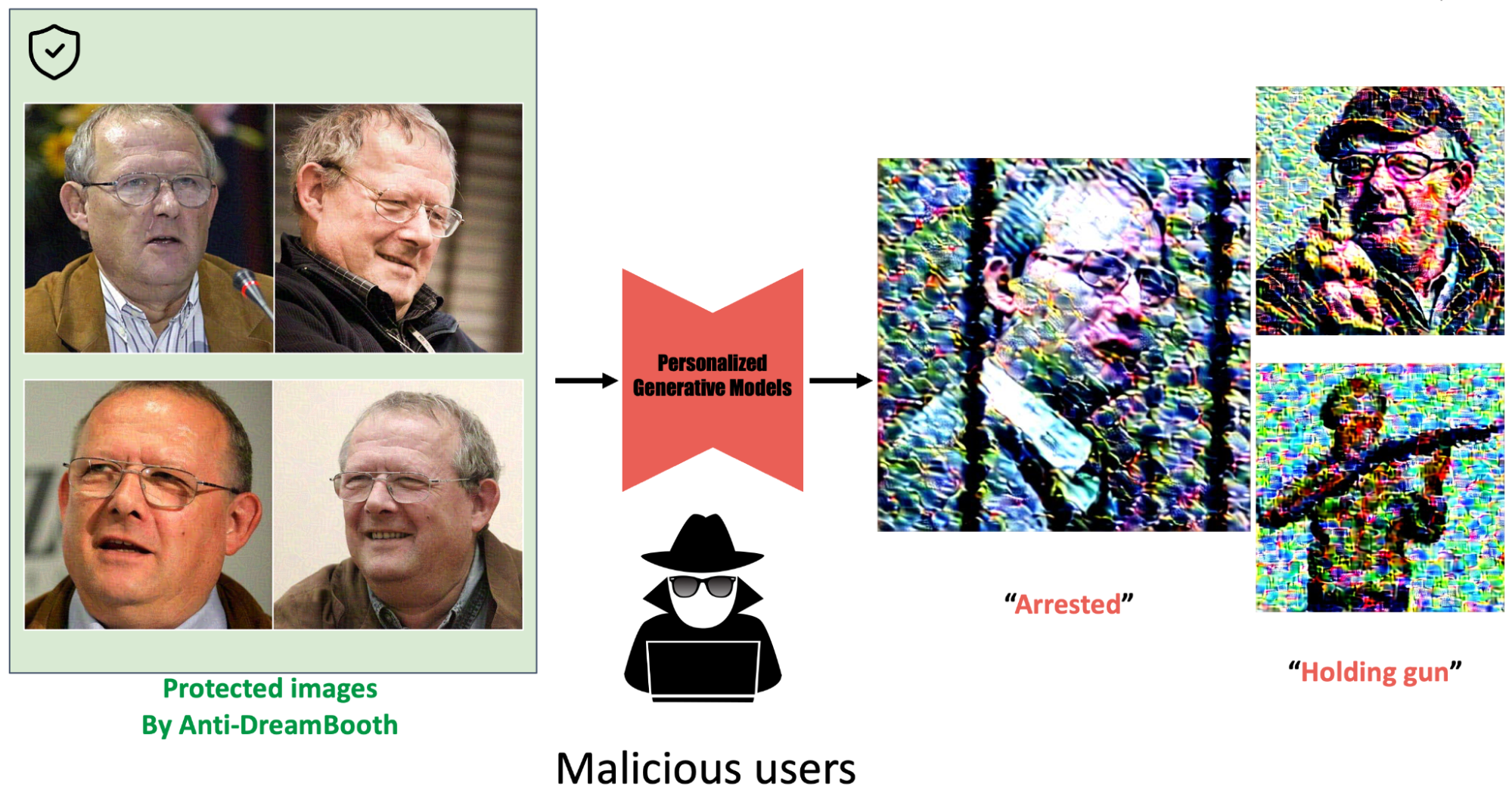
Figure 3: Our Anti-DreamBooth is a first approach to provide protection to users: Influenced by adversarial attacks, we add imperceptible noise to users’ images before publishing. This ensures that any personalized text-to-image models fine-tuned on these images can no longer generate realistic fake content of the targeted individual, regardless of the text prompt used.
3. Proposed Methods
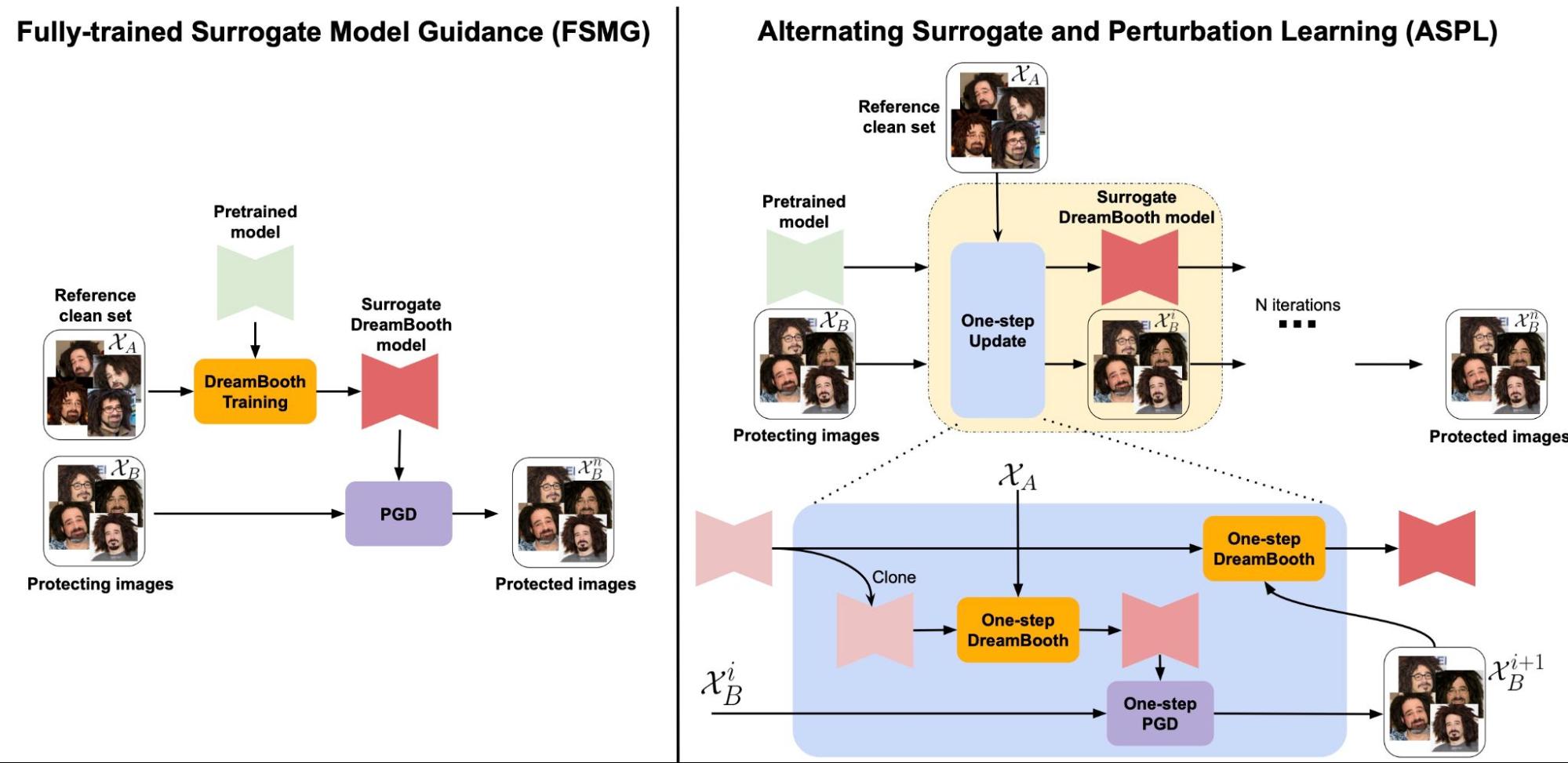
Figure 4: Two variants of Anti-DreamBooth: Fully-trained Surrogate Model Guidance (FSMG) and Alternating Surrogate and Perturbation Learning (ASPL).
The core of our approach lies in applying adversarial attack techniques to the diffusion process. We propose two main algorithms: Fully-trained Surrogate Model Guidance (FSMG) and Alternating Surrogate and Perturbation Learning (ASPL).
FSMG utilizes a fixed surrogate DreamBooth model, fully finetuned on a small subset of clean user images, to guide the optimization of adversarial noise for each target image.
ASPL alternates between surrogate model finetuning and perturbation learning, allowing the surrogate model to adapt to the evolving perturbations throughout the optimization process.
Additionally, we propose targeted approaches to pull the personalized model’s output closer to a semantically different target image and ensemble approaches that combine multiple surrogate models to enhance the transferability of the defense in adverse settings.
4. Experiments and Results
4.1 Experiment setup
We evaluate our method using CelebA-HQ [2] and VGGFace2 [3] datasets. We measure Face Detection Failure Rate (FDFR) using RetinaFace [4], Identity Score Matching (ISM) using ArcFace [5], and image quality using SER-FQA [6] and BRISQUE [7] metrics.
The experiments are conducted in three settings: convenient, adverse, and uncontrolled.
4.2 Results
Figure 5: Qualitative results of our proposed methods in a convenient setting.
In a convenient setting, our untargeted version of FSMG and ASPL significantly improved FDFR and decreased ISM, with ASPL performing the best overall. Our ASPL also demonstrated robust performance in the adverse setting, especially when using an ensemble of surrogate models (E-ASPL). However, in the uncontrolled setting, ASPL’s effectiveness decreased as the proportion of clean images increased, showcasing the challenge of defense in such scenarios.
4.3 Ablation study
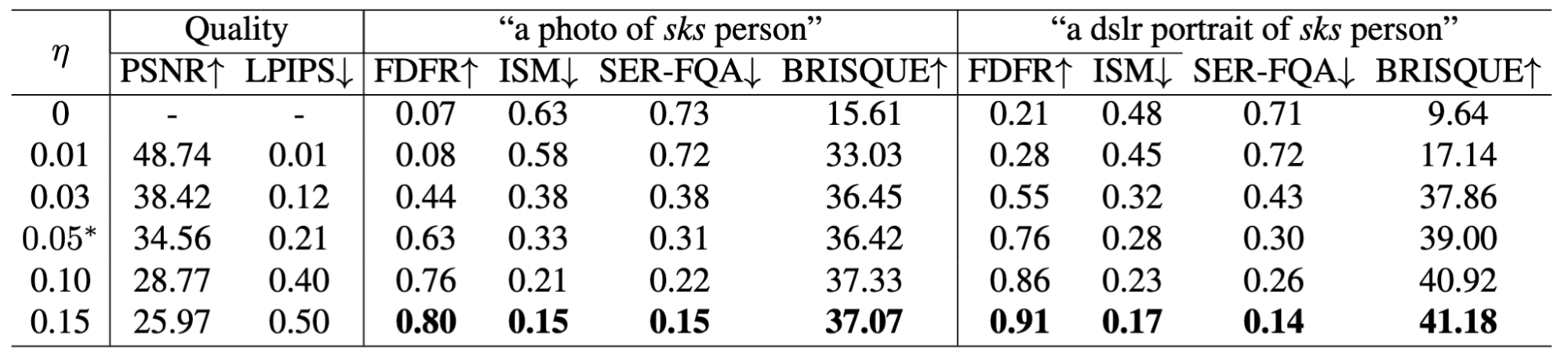
Table 1: Quality of protected images and defense performance of ASPL with different noise budgets on VGGFace2 in a convenient setting.
Our methods showed the consistent effectiveness of ASPL across different model versions, noise budgets, and inference prompts while maintaining good image’s quality, as indicated by reasonable PSNR and LPIPS scores.
5. Robustness evaluation
Figure 6: Qualitative result of our ASPL after applying different Gaussian Blur kernel size to the protected images and different JPEG compression. The overall quality of generated images remains low, with blurry texture and unnatural backgrounds.
Our method can withstand common image processing techniques like JPEG compression and Gaussian Blur, while still disrupting the generated images effectively.
6. Real-world applications
Figure 7: Disrupting personalized images generated by Astria [8] service.
Our method significantly reduces the quality of the generated images in various complex prompts and on both target models. This highlights the robustness of our approach, which can defend against online personalized image generation services without requiring knowledge of their underlying configurations.
Figure 8: Our method has also proven effective in preventing the imitation of artistic styles, which has become an emerging threat for online artists after the introduction of personalized text-to-image diffusion models.
7. Conclusions
We reveal a potential threat of misused personalized models and propose a framework to counter this threat. Our solution is to perturb users’ images with subtle adversarial noise so that any personalized text-to-image model trained on those images will produce poor personalized images. We designed several algorithms and extensively evaluated them in different settings. Our defense is effective, even in adverse conditions. In the future, we aim to improve the perturbation’s imperceptibility and robustness and conquer the uncontrolled settings.
8. References
[1] Ruiz, Nataniel, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. “Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22500-22510. 2023.
[2] Liu, Ziwei, Ping Luo, Xiaogang Wang, and Xiaoou Tang. “Deep learning face attributes in the wild.” In Proceedings of the IEEE international conference on computer vision, pp. 3730-3738. 2015.
[3] Cao, Qiong, Li Shen, Weidi Xie, Omkar M. Parkhi, and Andrew Zisserman. “Vggface2: A dataset for recognising faces across pose and age.” In 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018), pp. 67-74. IEEE, 2018.
[4] Deng, Jiankang, Jia Guo, Yuxiang Zhou, Jinke Yu, Irene Kotsia, and Stefanos Zafeiriou. “Retinaface: Single-stage dense face localisation in the wild.” arXiv preprint arXiv:1905.00641 (2019).
[5] Deng, Jiankang, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. “Arcface: Additive angular margin loss for deep face recognition.” In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4690-4699. 2019.
[6] Terhorst, Philipp, Jan Niklas Kolf, Naser Damer, Florian Kirchbuchner, and Arjan Kuijper. “SER-FIQ: Unsupervised estimation of face image quality based on stochastic embedding robustness.” In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5651-5660. 2020.
[7] Mittal, Anish, Anush Krishna Moorthy, and Alan Conrad Bovik. “No-reference image quality assessment in the spatial domain.” IEEE Transactions on image processing 21, no. 12 (2012): 4695-4708.